Edge Delta Deduplicate Logs Processor
9 minute read
Overview
The deduplicate logs processor is used to deduplicate identical logs discovered within a specified interval. Identical logs are those with the same body, attributes, and resources. This node is useful in scenarios where you want to reduce data volume.
Duplicate logs may come about as a result of parallel pipeline design or from systems upstream of the agent.
If duplicates are found, one instance will pass with a log_count attribute for the number of replicas dropped. The count attribute counts the number of dropped logs - two identical logs will result in a single log with a log_count attribute of 1. The timestamp is ignored so identical logs with different timestamps but within the same interval will be rolled up into a single log.
Use the configuration wizard below to generate a starter YAML configuration.
Example Configuration
In this example, all the logs in the input pane are duplicates. So they are compacted into a single log with an additional count field attributes["log_count"] showing the number of duplicates detected during the interval (100 in the case of live capture).
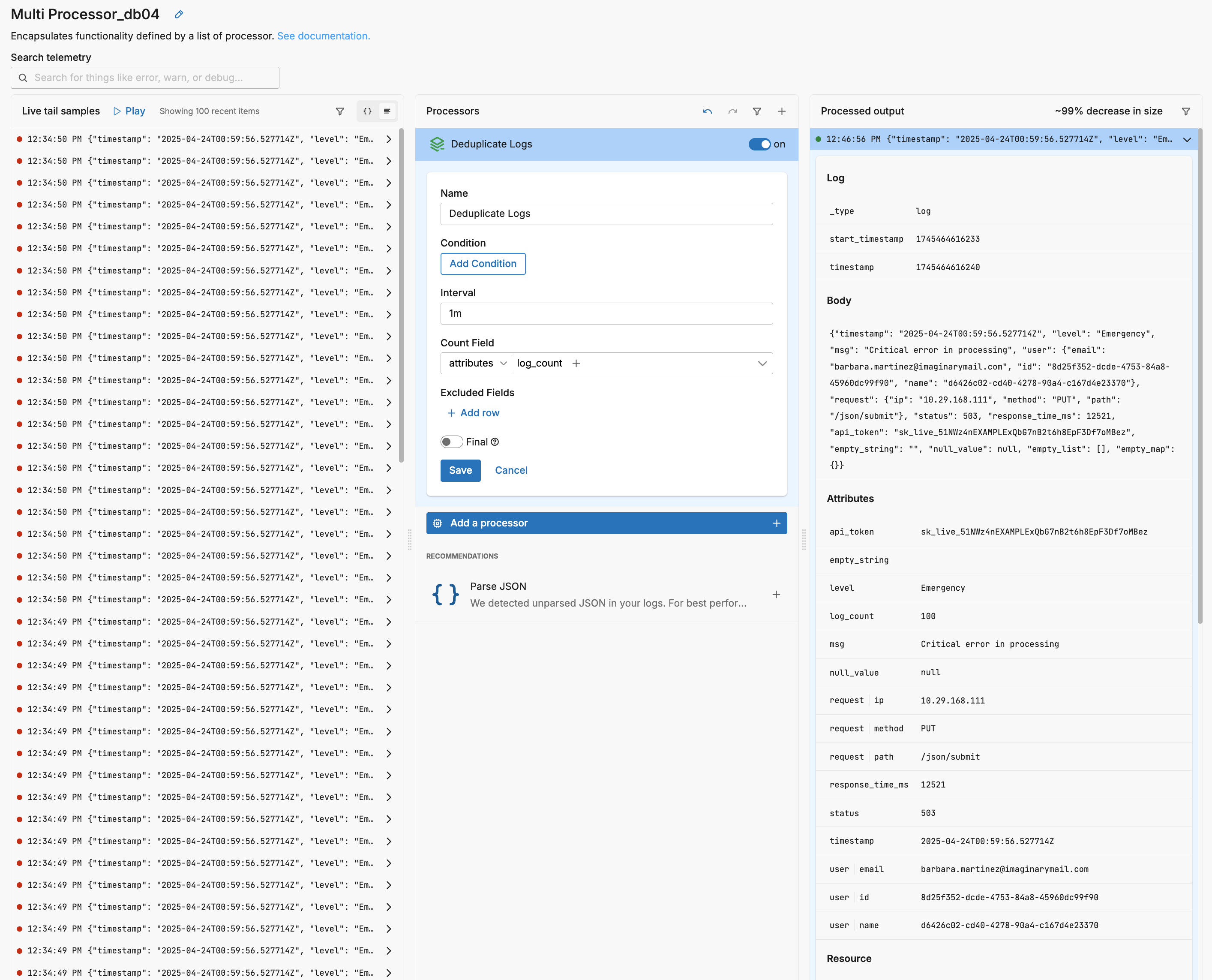
This configuration generates the following YAML:
- name: Multi Processor_db04
type: sequence
processors:
- type: dedup
metadata: '{"id":"AZERA9gNqbzo6gJsKeQs9","type":"dedup","name":"Deduplicate Logs"}'
data_types:
- log
interval: 1m0s
count_field_path: attributes["log_count"]
Options
condition
The condition parameter contains a conditional phrase of an OTTL statement. It restricts operation of the processor to only data items where the condition is met. Those data items that do not match the condition are passed without processing. You configure it in the interface and an OTTL condition is generated. It is optional.
Important: All conditions must be written on a single line in YAML. Multi-line conditions are not supported.
Comparison Operators
| Operator | Name | Description | Example |
|---|---|---|---|
== | Equal to | Returns true if both values are exactly the same | attributes["status"] == "OK" |
!= | Not equal to | Returns true if the values are not the same | attributes["level"] != "debug" |
> | Greater than | Returns true if the left value is greater than the right | attributes["duration_ms"] > 1000 |
>= | Greater than or equal | Returns true if the left value is greater than or equal to the right | attributes["score"] >= 90 |
< | Less than | Returns true if the left value is less than the right | attributes["load"] < 0.75 |
<= | Less than or equal | Returns true if the left value is less than or equal to the right | attributes["retries"] <= 3 |
matches | Regex match | Returns true if the string matches a regular expression (generates IsMatch function) | IsMatch(attributes["name"], ".*\\.log$") |
Logical Operators
Important: Use lowercase and, or, not - uppercase operators will cause errors!
| Operator | Description | Example |
|---|---|---|
and | Both conditions must be true | attributes["level"] == "ERROR" and attributes["status"] >= 500 |
or | At least one condition must be true | attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT" |
not | Negates the condition | not IsMatch(attributes["path"], "^/health") |
Functions
| Function | Description | Example |
|---|---|---|
IsMatch | Returns true if string matches the regex pattern | IsMatch(attributes["message"], "ERROR\|FATAL") |
Field Existence Checks
| Check | Description | Example |
|---|---|---|
!= nil | Field exists (not null) | attributes["user_id"] != nil |
== nil | Field doesn’t exist | attributes["optional_field"] == nil |
!= "" | Field is not empty string | attributes["message"] != "" |
Common Examples
- name: _multiprocessor
type: sequence
processors:
- type: <processor type>
# Simple equality check
condition: attributes["request"]["path"] == "/json/view"
- type: <processor type>
# Multiple values with OR
condition: attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT"
- type: <processor type>
# Excluding multiple values (NOT equal to multiple values)
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
- type: <processor type>
# Complex condition with AND/OR/NOT
condition: (attributes["level"] == "ERROR" or attributes["level"] == "FATAL") and attributes["env"] != "test"
- type: <processor type>
# Field existence and value check
condition: attributes["user_id"] != nil and attributes["user_id"] != ""
- type: <processor type>
# Regex matching on attributes
condition: IsMatch(attributes["path"], "^/api/") and not IsMatch(attributes["path"], "^/api/health")
- type: <processor type>
# Regex matching on body (case-insensitive)
condition: IsMatch(body, "(?i)error")
Common Mistakes to Avoid
# WRONG - Cannot use OR/AND with values directly
condition: attributes["log_type"] != "TRAFFIC" OR "THREAT"
# CORRECT - Must repeat the full comparison
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
# WRONG - Uppercase operators
condition: attributes["status"] == "error" AND attributes["level"] == "critical"
# CORRECT - Lowercase operators
condition: attributes["status"] == "error" and attributes["level"] == "critical"
# WRONG - Multi-line conditions
condition: |
attributes["level"] == "ERROR" and
attributes["status"] >= 500
# CORRECT - Single line (even if long)
condition: attributes["level"] == "ERROR" and attributes["status"] >= 500
interval
The interval parameter defines the window in which the node evaluates logs for duplicates. If one identical log falls within each interval it will not be dropped and rolled up. It is specified as a duration, the default is 30s and it is optional.
It is defined in YAML as follows:
- type: dedup
metadata: '{"id":"boLCEZZhdslDr2G6TFSp2","type":"dedup","name":"Deduplicate Logs"}'
interval: 1m0s
Count Field
The count_field_path parameter specifies the name of the attribute field that will contain the integer for the number of logs that were rolled up. You specify it in the tool and it is defined for you in YAML as a string. It is optional and the default is log_count.
It is defined in YAML as follows:
- type: dedup
metadata: '{"id":"boLCEZZhdslDr2G6TFSp2","type":"dedup","name":"Deduplicate Logs"}'
count_field_path: <path to field>
Excluded Fields
The excluded_field_paths parameter specifies the fields that should not be evaluated for variation. This means that even if these fields are different, the log might be rolled up. You specify one or more items in the tool, which generates a list in the YAML and it is optional. By default, the timestamp is excluded while the body field cannot be excluded.
It is defined in YAML as follows:
- type: dedup
metadata: '{"id":"boLCEZZhdslDr2G6TFSp2","type":"dedup","name":"Deduplicate Logs"}'
excluded_field_paths:
- attributes["level"]
Final
Determines whether successfully processed data items should continue through the remaining processors in the same processor stack. If final is set to true, data items output by this processor are not passed to subsequent processors within the node—they are instead emitted to downstream nodes in the pipeline (e.g., a destination). Failed items are always passed to the next processor, regardless of this setting.
The UI provides a slider to configure this setting. The default is false. It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
final: true
Configuration Wizard
Use this interactive wizard to generate a starter configuration:
What's causing duplicate logs?
Understanding the source helps recommend the right settings.
See Also
- For an overview and to understand processor sequence flow, see Processors Overview
- To learn how to configure a processor, see Configure a Processor.
- For optimization strategies, see Best Practices for Edge Delta Processors.
- If you’re new to pipelines, start with the Pipeline Quickstart Overview or learn how to Configure a Pipeline.
- Looking to understand how processors interact with sources and destinations? Visit the Pipeline Overview.