Federation with Gateway Pipelines
7 minute read
Overview
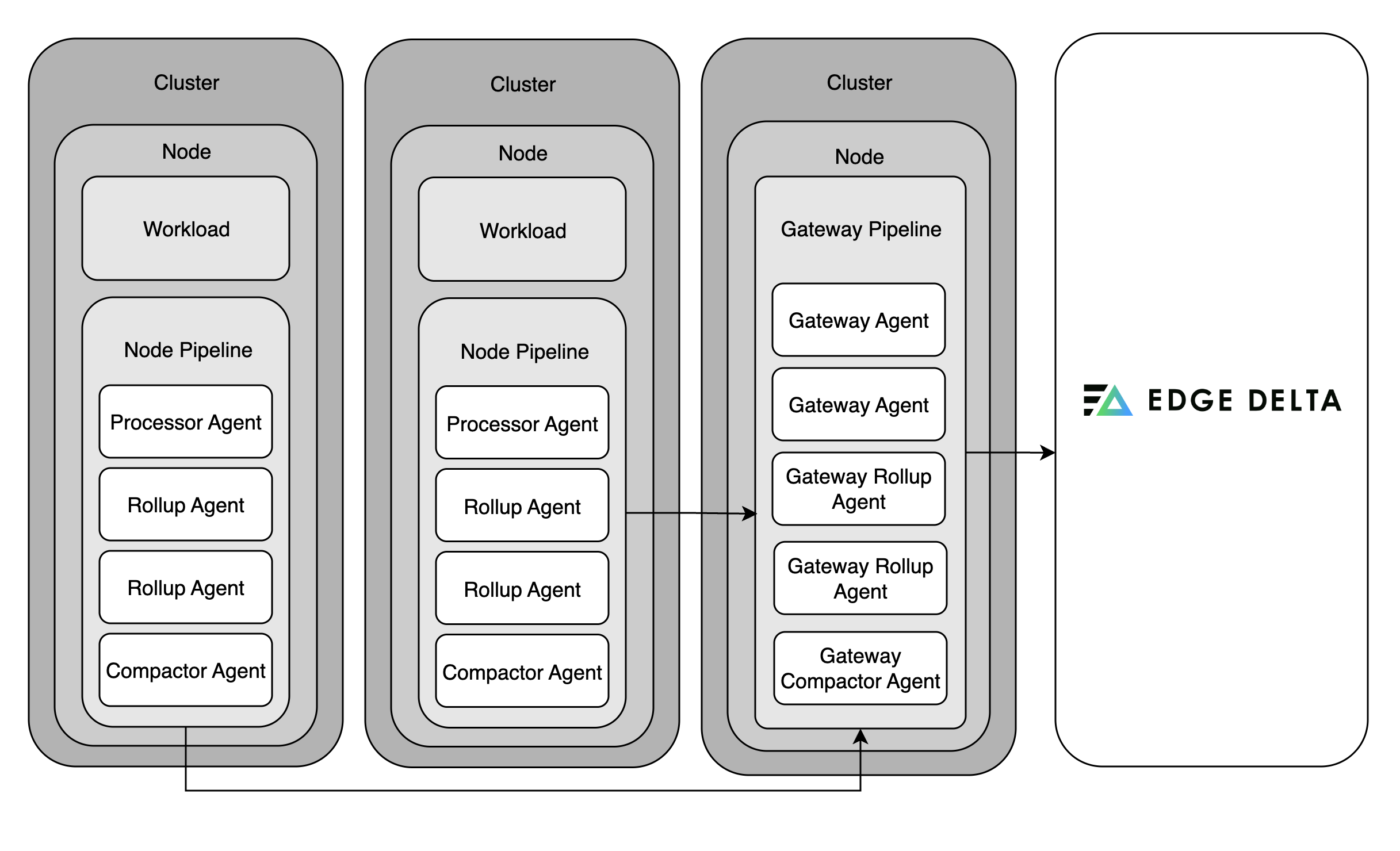
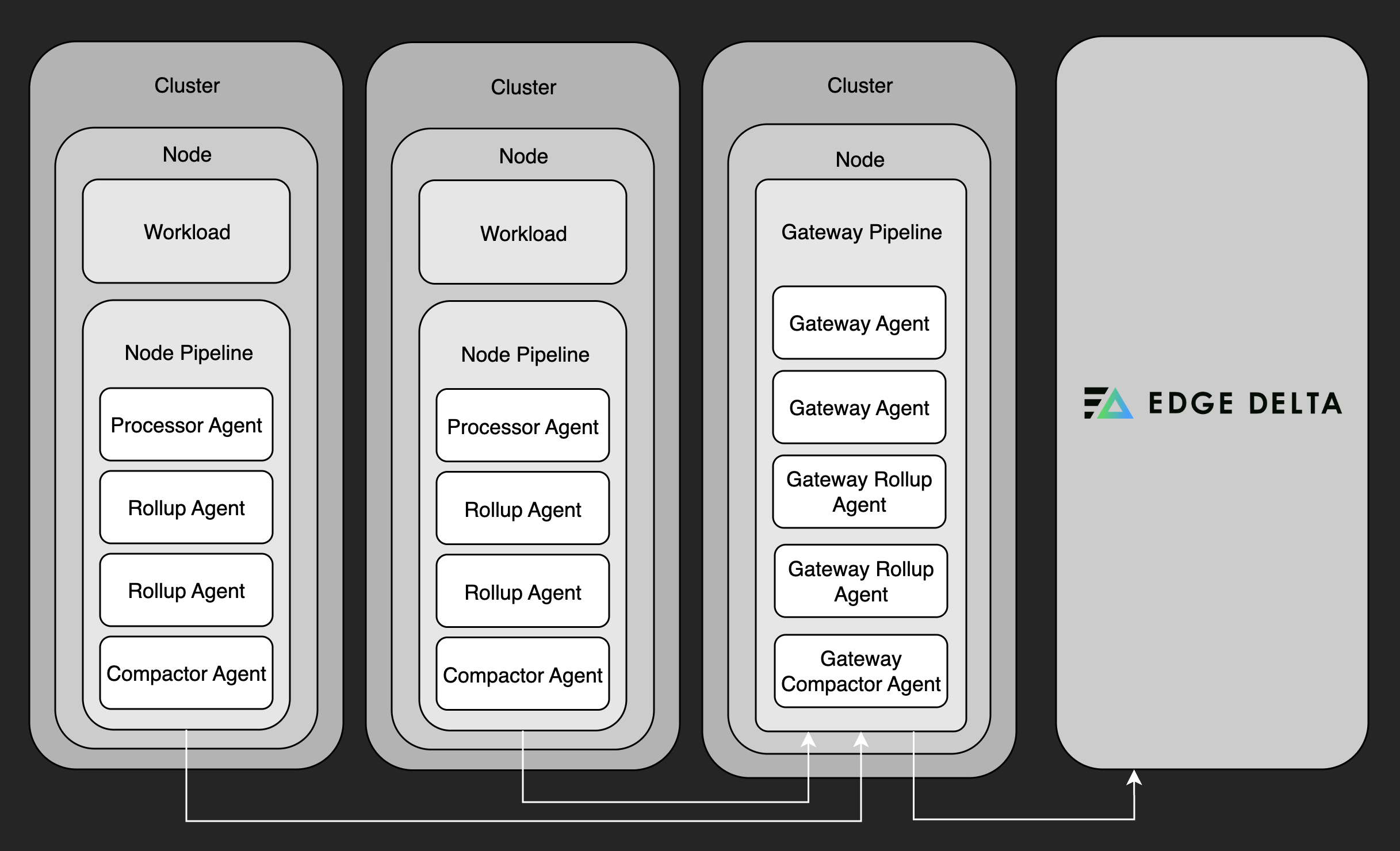
Edge Delta uses a modular pipeline approach to handle telemetry data inside Kubernetes environments. The node pipeline runs directly within your infrastructure, placing agents near the source of logs and metrics. These agents perform local processing, extracting key insights, compressing data, generating alerts, and rolling up metrics, before forwarding the results to the Edge Delta Observability Platform or other configured outputs.
The gateway pipeline serves as a central processing layer. It receives data from node agents and external systems, deduplicates logs, aggregates metrics, and enables cluster-wide visibility. You can deploy multiple gateway agents to handle different types of data or scale processing. Node and gateway pipelines connect through dedicated input and output nodes.
The coordinator pipeline handles cluster-level coordination. It manages backend communication, minimizes redundant processing, and uses the Kubernetes API to detect and group other pipeline agents. You deploy a single coordinator per cluster, in the same namespace as the node agents it manages.
See:
- Edge Delta Architecture - Pipeline types and organization
- Integrate Edge Delta’s Node, Coordinator, and Gateway Pipelines
- Edge Delta Pipeline Source
- Edge Delta Gateway Connection
- Monitoring and Visibility - Track pipeline health
Single Node Single Cluster
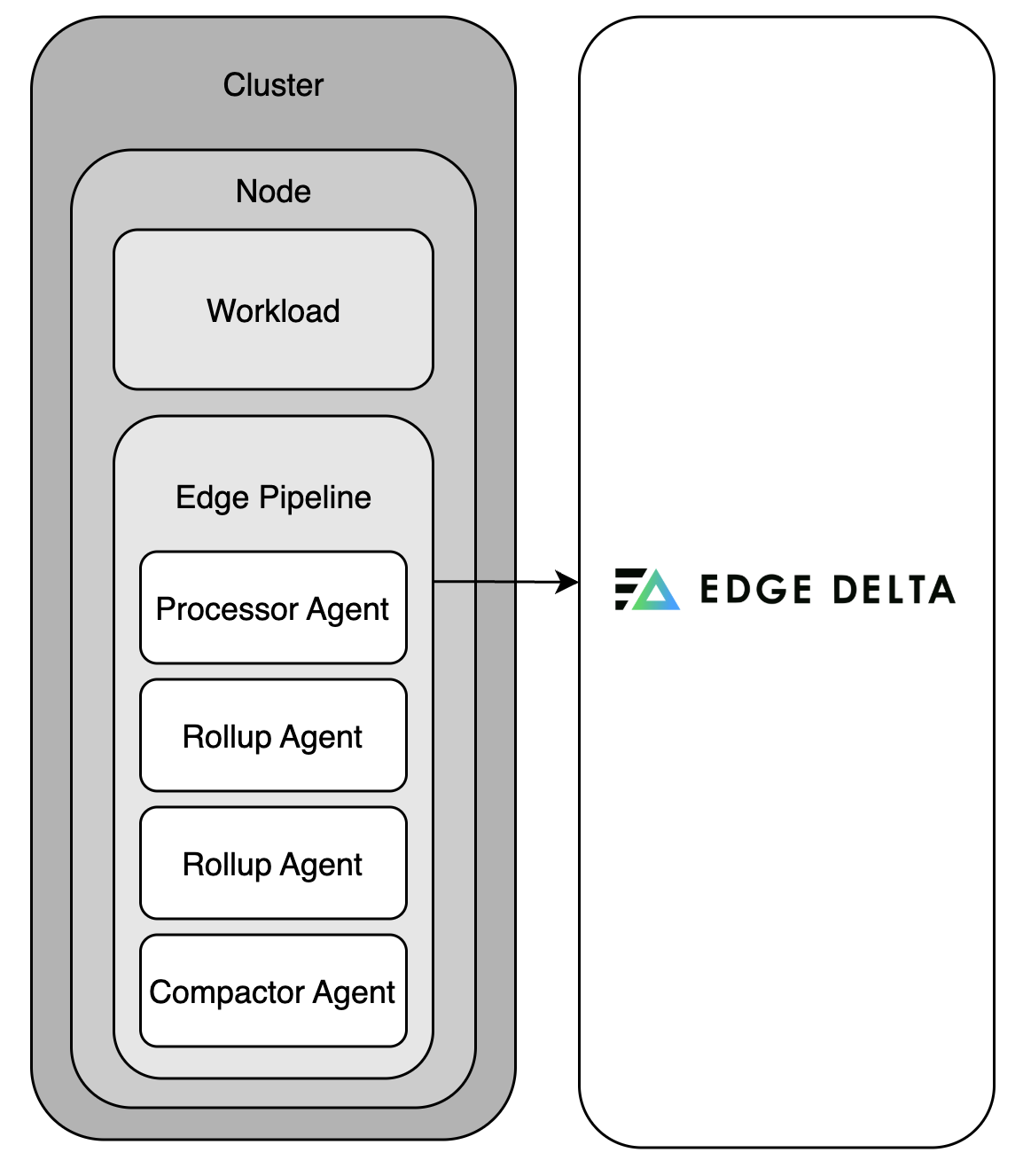
In a minimal deployment scenario, a node pipeline is installed on a standalone node or within a single-node Kubernetes cluster. The node pipeline operates locally on the host, collecting telemetry data and transmitting it directly to the Edge Delta Observability Platform. The environment is compact, self-contained, and does not require orchestration or aggregation. This configuration is ideal for proof-of-concept (POC) use cases, lightweight virtual machines, k3s clusters, or developer sandboxes, where simplicity and ease of deployment are paramount. It provides the fastest and most straightforward path to realizing value from Edge Delta without the added complexity of control-plane or aggregation components.
Multiple-Node Single Cluster
In large Kubernetes clusters, direct communication between each agent and the backend can become difficult to scale. As the number of nodes increases, tasks like live log tailing and cluster-wide data aggregation can suffer from latency and high overhead.
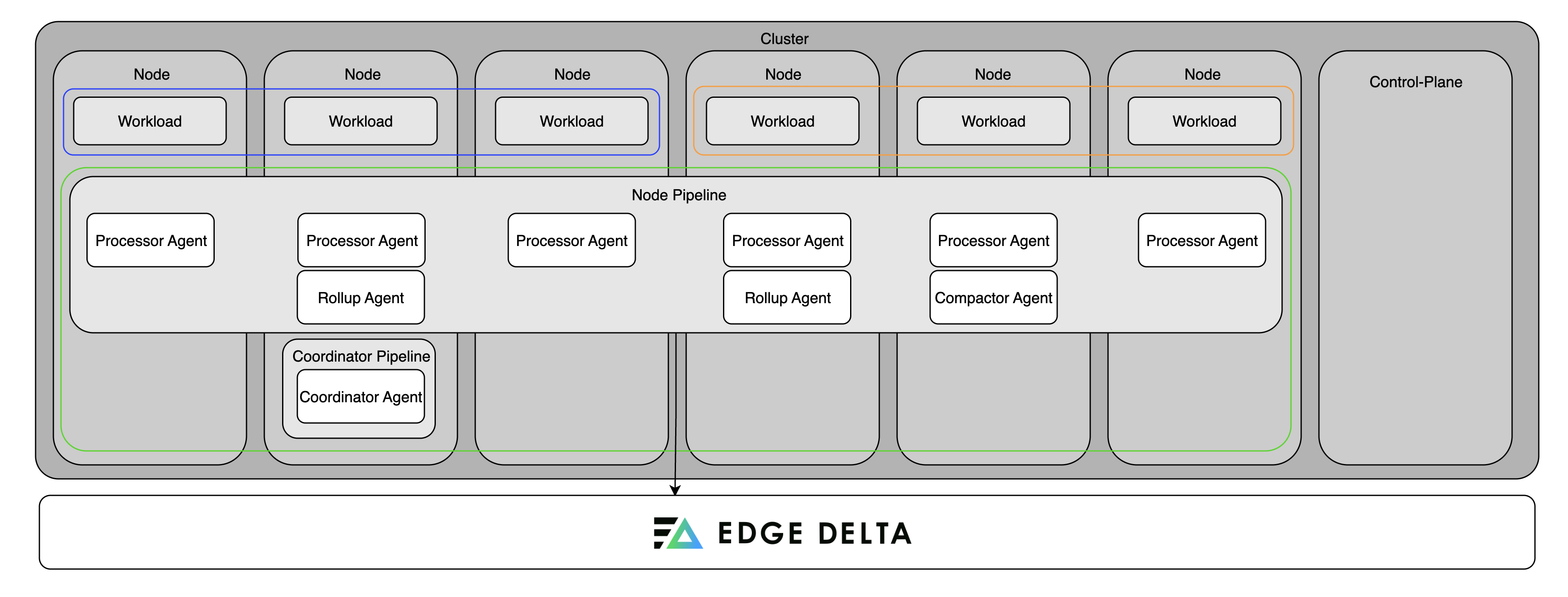
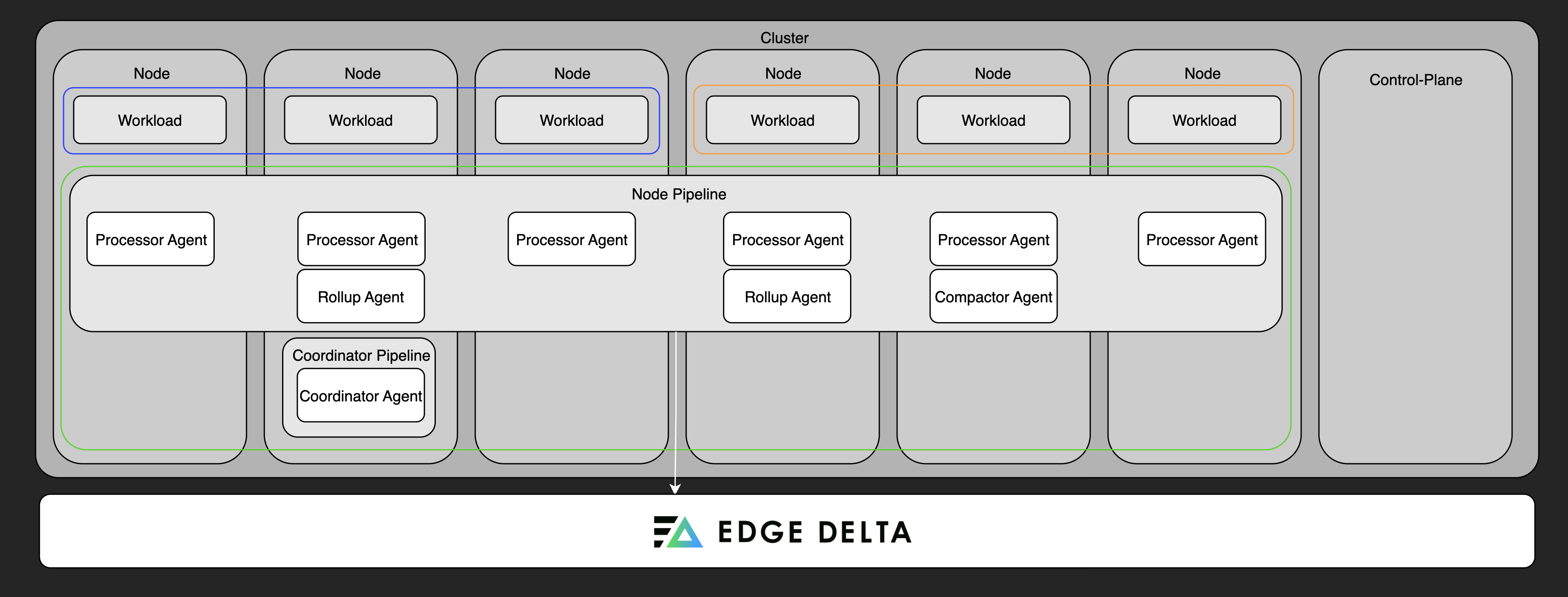
Adding a coordinator pipeline addresses this by introducing a single control-plane agent that manages backend communication for the entire cluster. It centralizes heartbeats and control messages, reducing noise and improving performance. The coordinator also handles leader election among the processor agents, ensuring that cluster-level operations are assigned efficiently. This setup streamlines communication with the backend, lowers operational overhead, and improves responsiveness for real-time features.
A coordinator is required for live tail to work in clusters with more than 20 nodes. For smaller clusters, a coordinator is optional but recommended for production deployments—it reduces backend overhead and improves live capture coverage across nodes.
Shared Kubernetes Platform with a Gateway
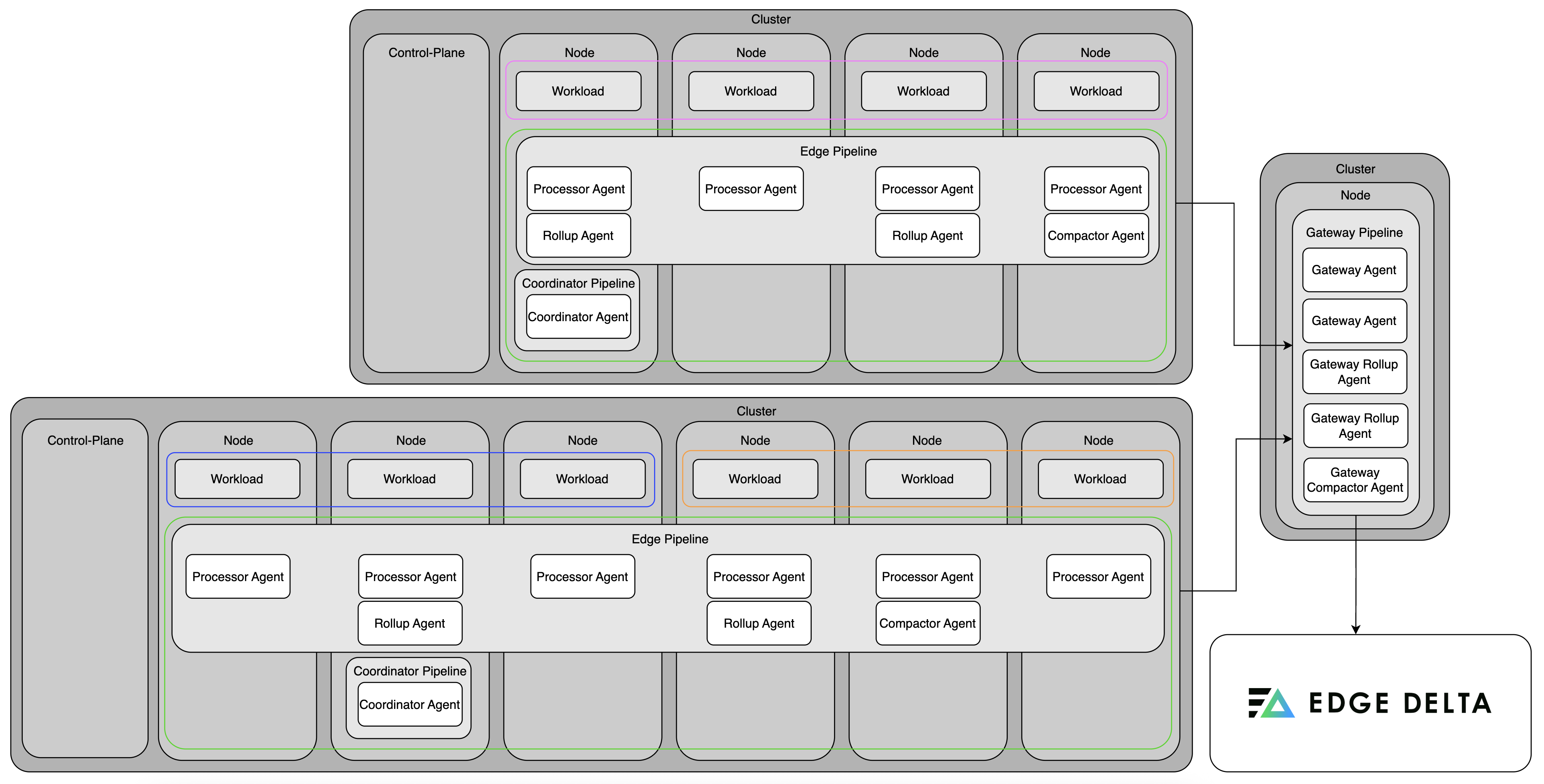
Note: The scenarios below demonstrate Gateway destination integration. The Gateway destination is available for all OS environment types. For Kubernetes edge pipelines, the gateway appears in an auto-populated dropdown list. For non-Kubernetes OS environments (Linux, Windows), manual configuration using DNS or static endpoints (such as via Kubernetes Ingress or NodePort) is required. A gateway pipeline can be deployed alongside the coordinator and node agents. In clusters with many nodes and multiple workloads, logs from different sources often contain redundant data, and accurate global metrics (like P95 latency or total error rate) require a unified view across all nodes.
The gateway acts as a central aggregation point, where it deduplicates data and runs metric aggregation and grouping to compute metrics at the cluster level. After processing, the gateway forwards the optimized data to the Edge Delta Observability Platform or any downstream destination. This reduces bandwidth usage and ingestion load, while ensuring that analysts and backend systems receive clean, aggregated data.
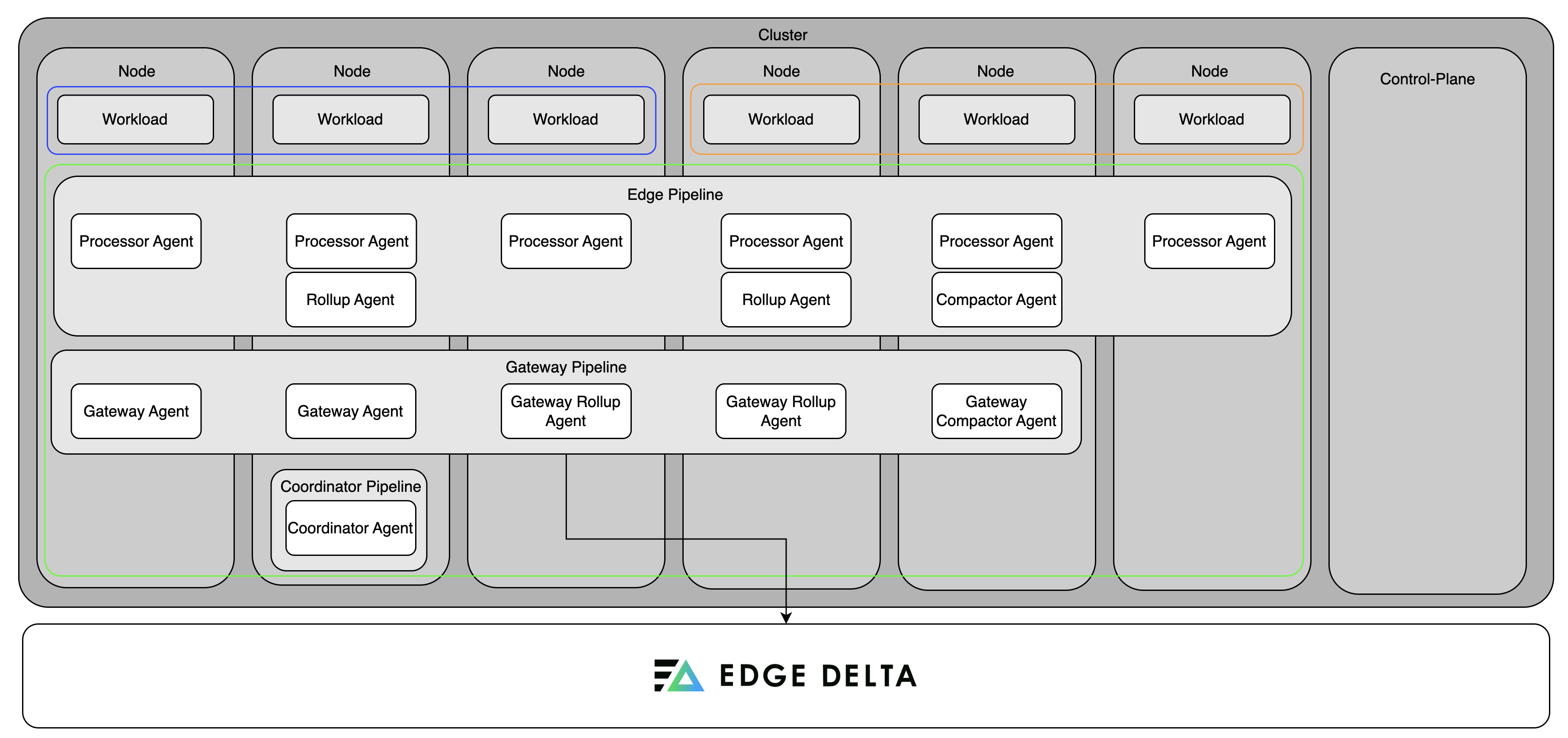
In this example, an organization uses a shared Kubernetes platform, internal teams deploy services in isolated namespaces (purple and orange) within a single cluster. The node pipeline runs in the edgedelta namespace (green), with processor agents deployed as a DaemonSet to collect host-level telemetry shared across all workloads. A singleton coordinator pipeline manages the cluster’s agents and handles control messages centrally. The gateway pipeline receives all telemetry from node agents, enabling accurate cluster-wide metric calculation and efficient data deduplication. This architecture supports multiple teams with strong namespace separation, centralized control, and scalable telemetry processing.
Multiple Clusters With a Gateway
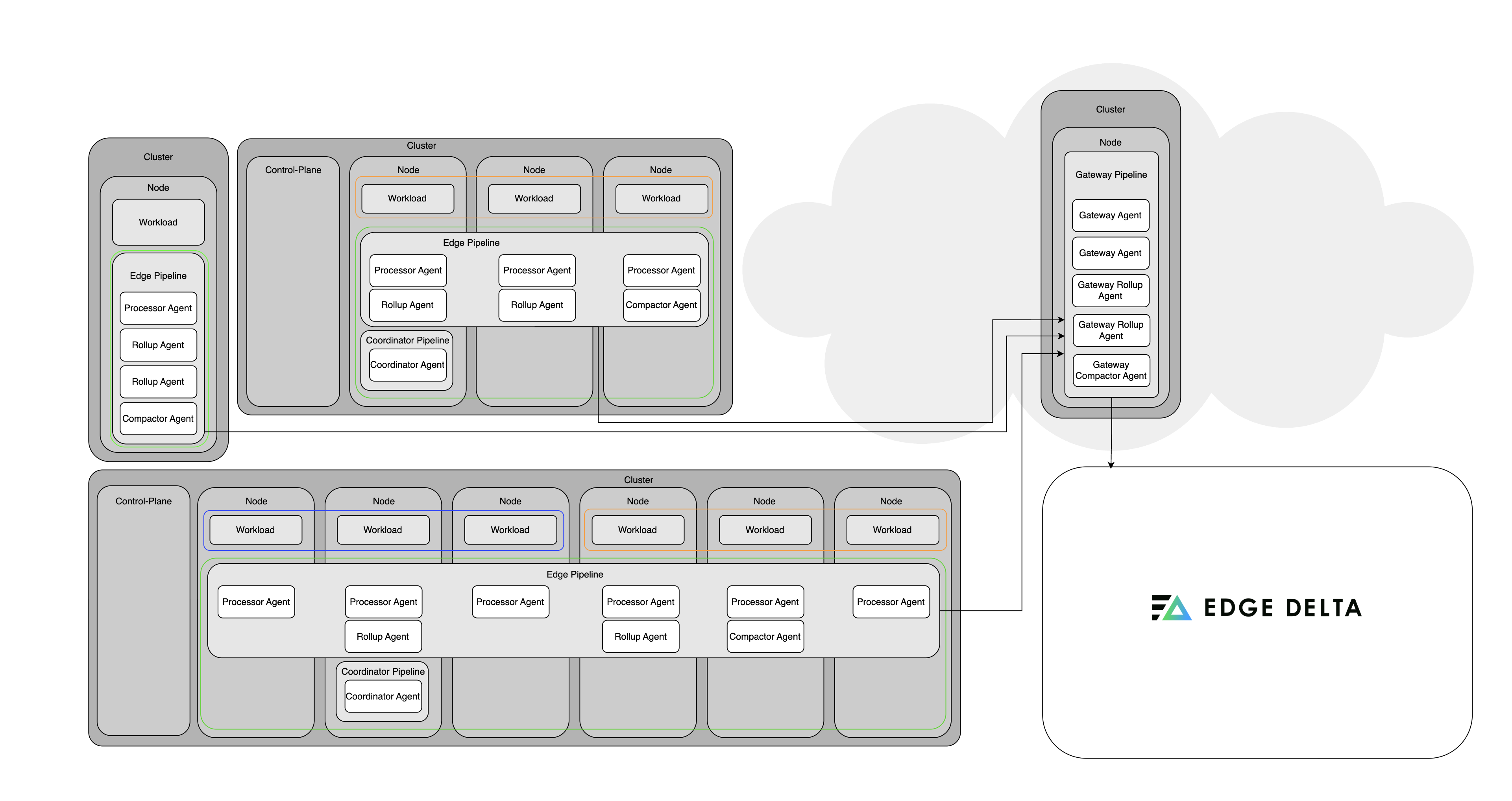
In environments where many single-node clusters are deployed, such as branch offices, retail sites, or other remote edge locations, centralizing telemetry aggregation through a shared gateway pipeline proves beneficial. Each cluster hosts a single node pipeline responsible for collecting local data. Instead of sending telemetry directly to the backend, these node pipelines forward data to a centrally deployed gateway pipeline via the Gateway Output. This gateway can be deployed either in one of the clusters or in a dedicated cluster. This setup balances lightweight local data collection with centralized processing without imposing additional overhead on each edge location.
Note: When multiple clusters send data to a shared gateway, ensure all node pipelines use
target_allocation_type: consistent(the default) to enable accurate cross-cluster metric aggregation. See Multi-Source Cluster Behavior for details.
Global Multi-Region Clusters
In an organization with Kubernetes-deployed microservices across multiple geographic regions to serve a global user base, deployment consists of clusters in different regions plus a gateway cluster. Node Agents are deployed on every node within these clusters, and each cluster is managed by a coordinator deployed as a singleton in the same edgedelta (green) namespace. Gateways can be optionally deployed per region for regional aggregation or centralized in one cluster for global telemetry aggregation. This setup offers region-local edge processing, cluster-level orchestration through the coordinator, flexibility in choosing between regional or centralized telemetry aggregation, and the avoidance of data duplication across regions.
Routing Note: With consistent routing (default), metrics from the same service across all regions will route to the same gateway pod, ensuring accurate global aggregation. See target_allocation_type for configuration details.
Hybrid Cloud Deployment
In an organization with in-store workloads, deployment involves local Kubernetes clusters in stores that sync data to a centralized cloud environment. Each store has on-prem clusters (workloads in orange and purple namepsaces) that connect to a central cloud-based cluster. In this setup, a Node Agent is positioned on each node within the in-store clusters, and a coordinator is optionally deployed per store cluster (for larger clusters), in the edgedelta (green) namespace. A gateway deployed in the cloud manages aggregation, with all node pipelines in store clusters forwarding data to this central gateway. This configuration offers several benefits, including local data processing within stores (at the edge), efficient data operations such as aggregation and persistence handled by the central cloud gateway, a minimal resource footprint within the stores, and resilience to connectivity issues since the gateway can buffer data.
High Compliance Requirements
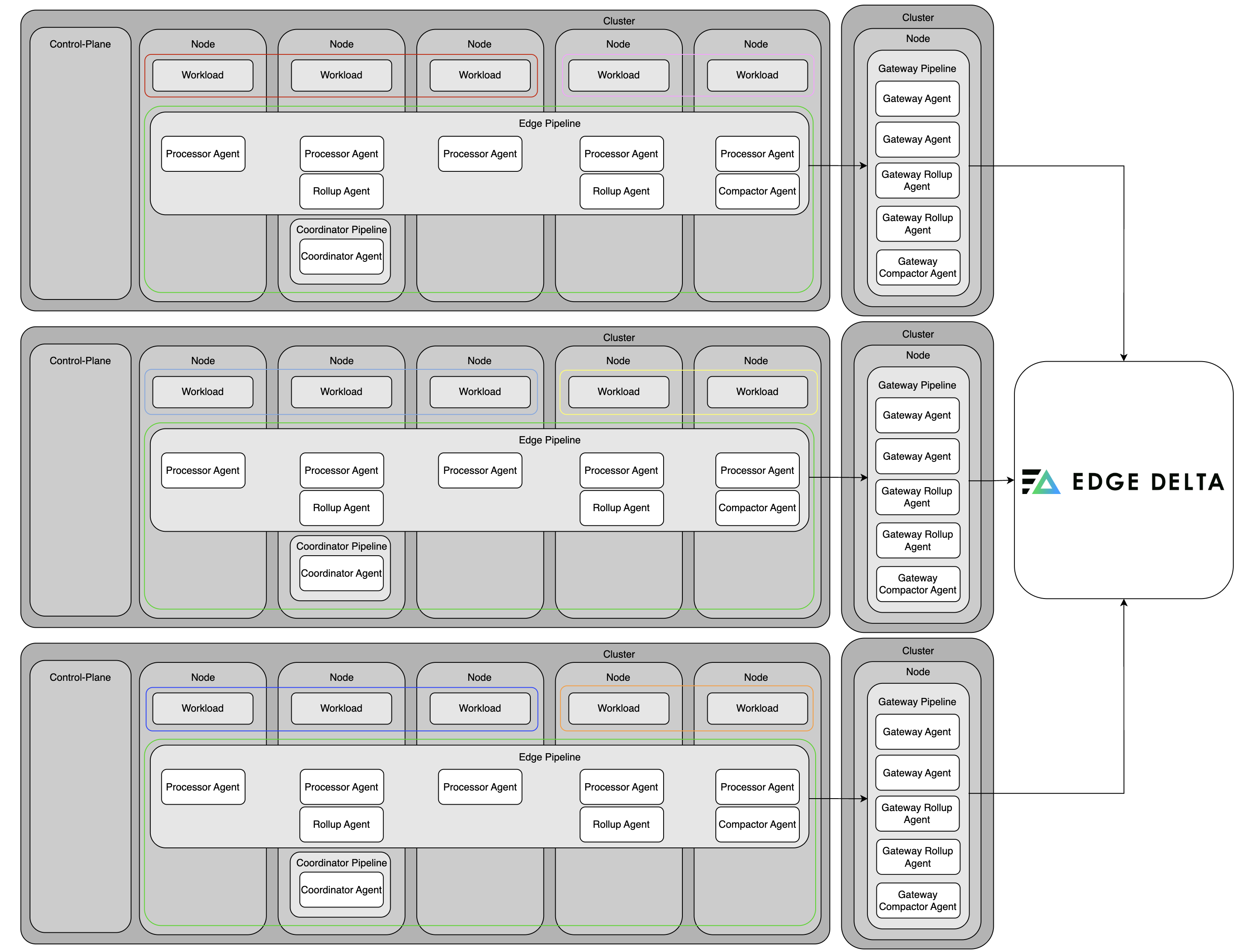
In an organization requiring strict control and auditability over telemetry pipelines, deployment involves isolated clusters for different environments such as dev, staging, and production, with distinct namespaces within clusters (e.g., prod-secure, prod-general). Node Agents are deployed on each node across all environments, and each cluster/environment is managed by a separate coordinator. Each environment has its own gateway, for example, a dev gateway or a prod gateway, backed by persistent volumes to ensure data resilience. This setup provides strict logical and physical isolation, simplifies compliance tracking, and allows coordinators to manage only their respective environments, while gateways take heavier processing load out of the main workload clusters.
Managed Services Provider (MSP) with Multi-Tenant Setup
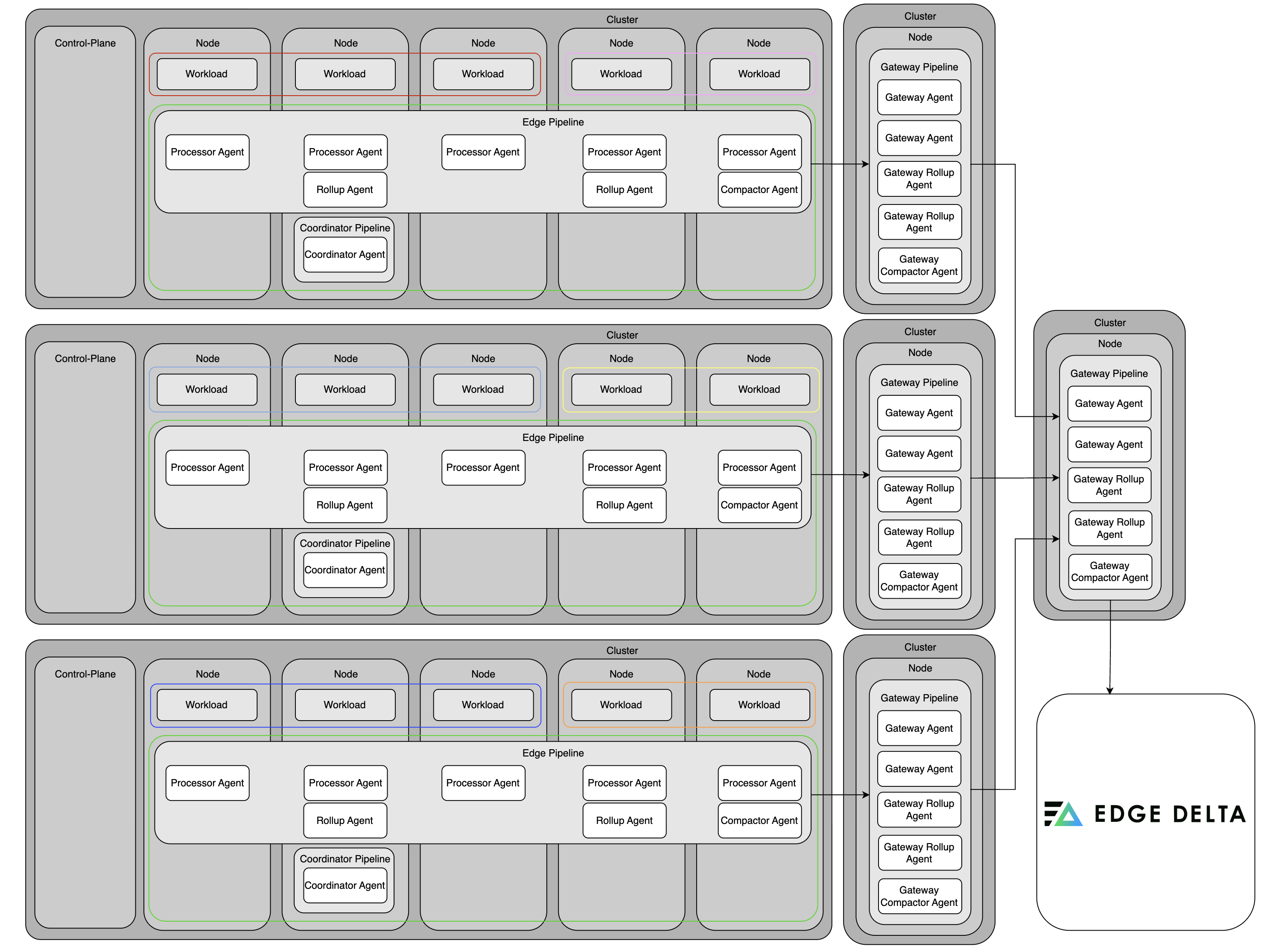
In an organization functioning as a Managed Services Provider (MSP) with a multi-tenant setup, deployment involves creating separate, isolated clusters for each customer to ensure central observability while maintaining tenant separation. Each customer’s cluster has node agents deployed per node, and a coordinator dedicated to the cluster. A centralized gateway is deployed in an MSP observability cluster, where each customer’s telemetry is routed through isolated pipeline paths using tenant-specific gateways. This configuration provides tenant-specific node and coordinator isolation, centralized management through a multi-tenant gateway, scalable and secure observability across multiple customers, and ensures compliance with customer data boundaries.