Model Context Protocol (MCP) Guide | Connect AI Agents to Your Systems
24 minute read
Overview
MCP gives Edge Delta a crisp seam between conversation and systems. It’s the contract that lets AI Team teammates discover sanctioned capabilities, pull just-enough context, and take actions without smuggling credentials or tribal knowledge into prompts. By putting every connector behind the same protocol surface, the AI Team can explain where evidence came from, which automations ran, and what guardrails applied before a human ever sees the result. Edge Delta layers organization-grade concerns on top of the baseline protocol (authorization checks, execution tracing, and data-residency controls) so teammates work within boundaries while still moving quickly.
MCP in Brief
MCP draws a clear boundary between intent and execution. The client expresses what it wants in terms of capabilities; the server decides how to satisfy those requests against whatever systems sit behind it. This separation means you can evolve back-end integrations without perturbing the conversational layer, and you can change models without re-plumbing your estate.
The host application (Edge Delta’s AI Team) creates one MCP client for each MCP server, maintaining dedicated one-to-one connections. Clients handle discovery and invocation on behalf of the user; servers expose tools, resources, and prompts backed by actual systems.
Note: Throughout this document, host application refers to Edge Delta’s AI Team—the runtime that provides the conversational experience and orchestrates teammate interactions.
Three core primitives carry most of the weight:
- Tools are invocable operations with typed inputs and outputs. They’re the verbs of the system: search a corpus, open a ticket, read a dashboard. Tools enable AI models to perform actions, with each tool defining a specific operation using JSON Schema for validation. Well-behaved tools are explicit about side effects and designed for idempotency so clients can retry without fear; when work is long-running, tools return resource URIs (and optionally support subscriptions) that the client can dereference or subscribe to rather than stuffing bulky results into the model’s prompt. Tools may declare an
outputSchemaand clients should validate structured results when present. See the MCP Tools specification for details. - Resources are the nouns: stable references to documents or domain objects that can be fetched, paged, or sliced as needed. Resources provide structured access to information from files, APIs, databases, or any other source. Each resource has a unique URI (like
file:///path/to/document.md) and declares its MIME type for appropriate content handling. Servers may expose resource templates (resources/templates/list) for parameterized URIs and provide autocompletion through the completion API. See the MCP Resources specification for details. Resources help conversations point at the same thing over time (“that pipeline revision”, “this anomaly cluster”) instead of copying large blobs into the context window. - Prompts are reusable templates that help structure interactions with language models. Prompts are templates and snippets that servers curate to encode domain knowledge such as query patterns, diagnostic checklists, and escalation summaries. Clients can parameterize these at runtime, which keeps conversational scaffolding close to the systems it describes rather than scattered through application code.
For more details about MCP architecture and primitives, see the official MCP specification.
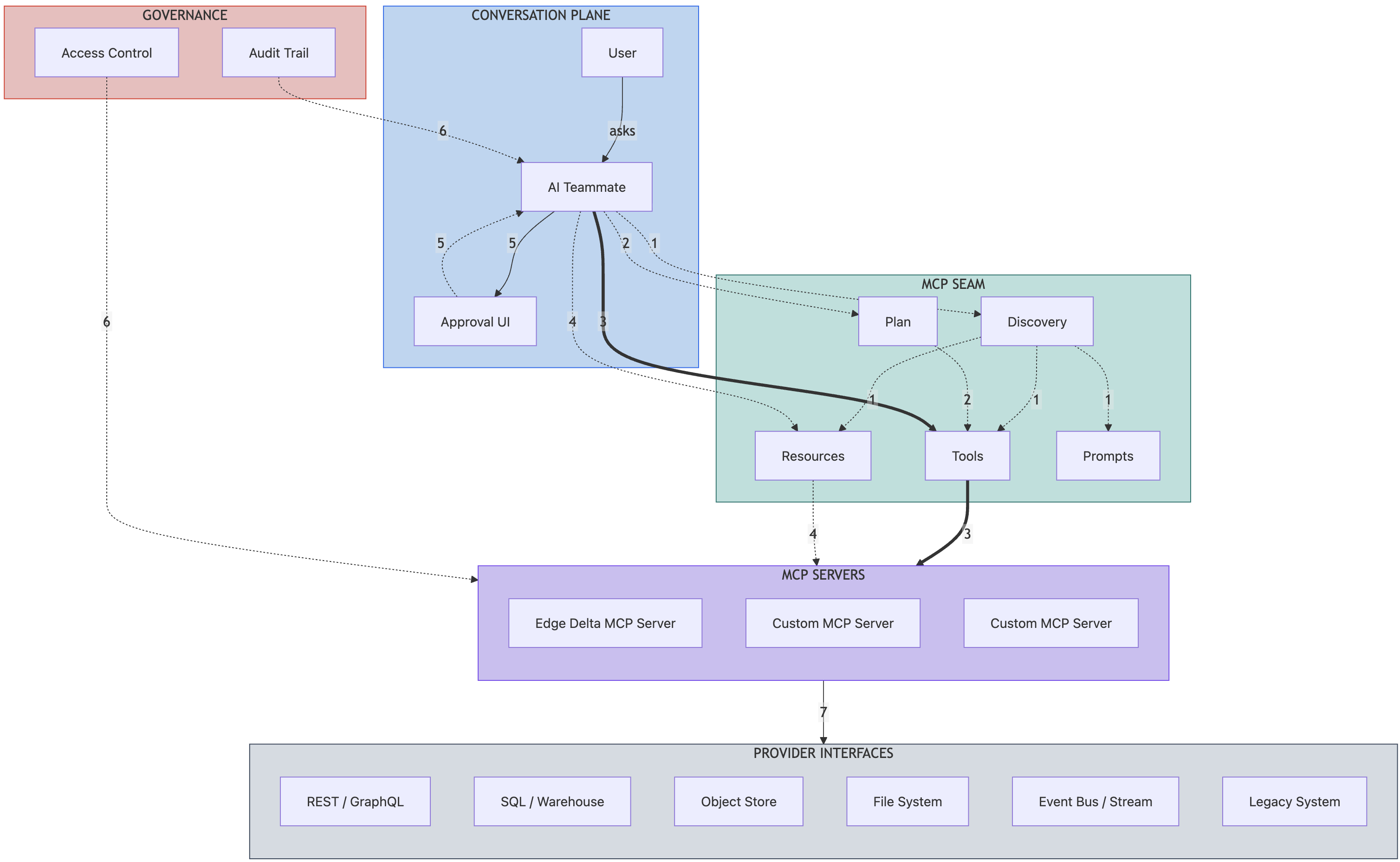
At the top sits the conversation plane, where users interact with AI teammates and approval interfaces. Below that, the MCP seam layer handles discovery, planning, tools, resources, and prompts. The third tier contains the MCP servers themselves, while the bottom tier shows provider interfaces including REST/GraphQL APIs, SQL databases, object stores, file systems, event buses and streams, and legacy systems. Governance controls for audit trails and access control attach at the client and server boundaries. Numbered flows (1–7) trace the path from discovery and planning through tool invocation and resource fetching, then to human approval, governance enforcement, and finally server-to-provider translation.
Diagram Key:
| Component | Description |
|---|---|
| User | Human interacting with the AI Team through conversation |
| AI Teammate | MCP client acting on behalf of the user, orchestrating all discovery, planning, and execution |
| Approval UI | Edge Delta UI where humans review and approve higher-risk actions |
| Discovery | Capability listing phase where the client learns what tools, resources, and prompts are available from connected servers |
| Plan | Client selects minimal set of operations, preferring resource handles over full payloads to conserve context |
| Tools | Invocable operations with typed inputs/outputs that perform actions across the MCP boundary (e.g., querying data, creating records, retrieving configurations) |
| Resources | Stable URI references to data that can be dereferenced on demand (e.g., resource://type/identifier, data://category/item-id) |
| Prompts | Reusable templates encoding domain knowledge and workflow patterns (e.g., investigation checklists, analysis workflows) |
| Edge Delta MCP Server | First-party MCP server exposing Edge Delta telemetry pipelines, dashboards, and operational data with full governance |
| Custom MCP Server | Custom or third-party MCP servers adapting proprietary systems, legacy platforms, or vendor APIs |
| REST / GraphQL | HTTP APIs providing structured access to cloud services, SaaS platforms, or internal microservices |
| SQL / Warehouse (read‑only or governed writes) | Relational databases, data warehouses (PostgreSQL, Snowflake) accessed through read-only or controlled queries |
| Object Store | Blob storage systems (S3, Azure Blob, GCS) for logs, artifacts, or unstructured data |
| File System | Local or mounted filesystems for configuration files, scripts, or application state |
| Event Bus / Stream | Message brokers, event buses (Kafka, Kinesis, Pub/Sub) for real-time telemetry or event correlation |
| Legacy System | Mainframes, batch job schedulers, or homegrown systems requiring protocol translation |
| Audit Trail | Request/response logging with timestamps and initiating identity for compliance, post-incident review, and debugging |
| Access Control | RBAC enforcement, data masking, residency controls, and activity logging applied at the server boundary |
How the MCP Seam Works:
Connect & Discover — When the AI Teammate (MCP client) starts a session, it connects to each available MCP server and sends
tools/list,resources/list, andprompts/listrequests. Servers respond with their complete capability catalogs, including tool schemas with typed inputs and outputs, resource URIs with MIME types, and prompt templates with parameter definitions. The discovery phase happens once per session and gives the client a full inventory of what it can do across all connected systems. The client never talks directly to the provider interfaces—all capability discovery flows through the MCP servers, which control what gets exposed.Plan — Armed with the catalog, the client plans its approach to answering the user’s question. Planning is conservative: bring back only what will fit in the context window, prefer resource handles over full payloads, and defer expensive tool calls until there’s evidence they’re needed. For example, instead of fetching an entire configuration document, the client might request just a resource handle (like
config://service-name/component) and only dereference it if the conversation requires those specific settings.Act via Tools — To perform actions, the client invokes tools by sending
tools/callrequests across the MCP seam to the servers. Each call specifies the tool name and provides arguments that match the tool’s schema. The MCP servers receive these requests, apply governance controls, and translate them into operations against the backing provider interfaces (REST APIs, databases, object stores, etc.). Servers execute the requested operations and return structured results or handles for long-running work. These are heavy operations that cross system boundaries and may modify state, but the client remains decoupled from the underlying implementation.Fetch by Handle — When the client needs specific context, it dereferences resource handles using
resources/readrequests sent to the MCP servers. Instead of copying large blobs into the prompt, resources act as lightweight pointers. A server might expose resources likeconfig://<type>/<version>for configuration snapshots orevent://<category>/<identifier>for specific events—the URI scheme is defined by each server. The server fetches the data from the appropriate provider interface, applies masking and access controls, and returns only what the client is authorized to see. This keeps conversations terse while still grounded in live data.Explain & Approve — For higher-risk actions, the teammate doesn’t execute immediately. Instead, it packages the original user request, the derived insight from tool results and resources, and the proposed change into a structured message sent to Slack or the Edge Delta UI. Humans review the full context, approve or modify the plan, and send their decision back to the teammate. This human-in-the-loop step ensures critical operations like pipeline deployments or ticket escalations carry proper oversight without losing the reasoning trail.
Trace & Govern — Governance enforcement happens at the client and server boundaries where Edge Delta’s controls are applied. Each MCP request and response is captured with timestamps and the initiating teammate identity, creating an audit trail for post-incident review or compliance checks. RBAC rules determine which teammates can access which MCP servers and which tools they can invoke. Masking is applied at the server boundary before payloads cross back to the client, respecting data classification policies. Edge Delta enforces residency controls for data it processes and returns via MCP; provider-side residency depends on the underlying system’s configuration.
Translate to Provider Interfaces — MCP servers act as anti-corruption layers, translating clean MCP contracts into whatever protocols the backing provider interfaces require. When a tool call or resource request arrives at an MCP server, the server translates it to the appropriate provider interface protocol—REST/GraphQL API calls, SQL queries, S3 operations, filesystem reads, event stream subscriptions, or even mainframe transactions—while keeping the client isolated from those implementation details. This layer is where vendor-specific authentication, rate limiting, retry logic, and error translation happen, ensuring that changes to underlying systems don’t ripple back through the MCP boundary.
Protocol Mechanics
MCP uses JSON-RPC 2.0 over two standard transports: stdio (for local processes) and Streamable HTTP (for remote servers with standard HTTP authentication). Streamable HTTP may use an Mcp-Session-Id header for stateful sessions.
Lifecycle: The connection follows a three-step handshake: the client calls initialize, the server responds with its capabilities, and the client sends notifications/initialized to signal readiness. When establishing a connection, the client calls initialize with the protocol version and supported capabilities. The server responds with its own capabilities, allowing both sides to understand what features are available. After a successful handshake, the client sends notifications/initialized to signal readiness. This ensures clients don’t attempt unsupported operations and enables efficient communication.
Discovery: The client sends tools/list, resources/list, and prompts/list requests. Servers respond with their complete capability catalogs, including tool schemas with typed inputs and outputs, resource URIs with MIME types, and prompt templates with parameter definitions. The client learns enough schema and metadata to plan conservatively: bring back only what will fit, prefer resource URIs over payloads, and defer expensive calls until there’s evidence they’re needed.
Execution: The client invokes tools via tools/call, fetches resources via resources/read, and retrieves prompts via prompts/get. Servers may send notifications when capabilities change (notifications/tools/list_changed, notifications/resources/list_changed, notifications/prompts/list_changed); subscription support is optional and server-specific. Every answer can point to the artifacts it used, and every action can be traced back to the inputs that motivated it.
Because MCP is agnostic to programming language and transport, it lends itself to evolutionary architecture. Teams mix single‑domain, aggregator, and adapter patterns to match organizational boundaries and system realities; the point is to keep the seam crisp so you can rearrange topology as needs change.
A typical flow reads like a short narrative. A teammate receives a question, uses capability discovery to decide whether correlation or configuration is likely, calls a small number of tools to test that hypothesis, and then fetches the specific resources needed to justify an answer. If the question pivots (perhaps the result suggests a different service is to blame), the client re‑plans with the same handles in hand, so context doesn’t collapse with the change in direction. All of this leaves a trail: which capabilities were consulted, which artifacts were read, which actions were proposed. That trace is useful for debugging the teammate’s reasoning and for satisfying governance needs when changes touch production systems. In Edge Delta’s implementation, the same contract underpins connectors for telemetry pipelines, dashboards, and event sources, allowing AI teammates to cite evidence and record their steps without leaking beyond organizational policy.
There are trade‑offs to respect. Coarse tools are easy to reason about but can force clients to over‑fetch; overly fine‑grained tools reduce payload size but increase chattiness and coordination complexity. Returning raw data makes models flexible but increases prompt pressure; returning summaries reduces size but risks losing crucial detail. Good servers version their schemas, document error semantics, and make side effects explicit; good clients treat tools as unreliable networks do, with retries, backoff, and a bias toward idempotent patterns. When those habits are in place, MCP gives you a clean seam where conversations, systems, and governance concerns can evolve independently without tangled coupling.
MCP as the Connector Ecosystem Foundation
The operational landscape organizations navigate includes dozens of specialized systems: cloud platforms, incident management, version control, CI/CD pipelines, security tools, collaboration platforms, and observability backends. Each exposes distinct APIs with different authentication models, data schemas, and operational semantics. Traditional integration approaches hard-code these details into application logic, creating brittle coupling that requires redeployment when APIs change or new systems enter the portfolio.
MCP inverts this relationship by establishing a universal adapter layer. Instead of building point-to-point integrations between the AI Team and every external system, Edge Delta implements MCP servers that expose standardized tools and resources while abstracting vendor-specific details. The AI Team discovers capabilities through uniform MCP protocols—tools/list, resources/list, prompts/list—without awareness of whether those capabilities are backed by GitHub’s REST API, PagerDuty’s event stream, AWS SDKs, or a legacy mainframe.
This architecture enables Edge Delta to expand the connector ecosystem rapidly. When a new integration becomes valuable—whether a vendor providing an official MCP server, a customer deploying a custom adapter, or Edge Delta building native support—teammates gain access through the same discovery and invocation patterns they already understand. Organizations can integrate proprietary systems or niche vendors without waiting for official connector releases, accelerating time-to-value for specialized workflows.
The connector ecosystem grows in two directions:
Streaming connectors continuously ingest telemetry—logs, metrics, traces, events—from infrastructure and applications. These connectors integrate with Edge Delta’s telemetry pipelines, where processors apply parsing, enrichment, masking, and routing before data reaches storage or downstream destinations. AI teammates query this telemetry through the Edge Delta MCP connector, which exposes it via tools like log search, metric correlation, and trace analysis. Streaming data flows through proven pipeline infrastructure with established governance controls.
Event connectors deliver discrete, actionable signals: PagerDuty incidents, GitHub pull requests, AWS EventBridge notifications, security alerts. These connectors trigger AI Team workflows directly, enabling teammates to initiate investigations autonomously when conditions warrant attention. Event connectors route through a dedicated AI Team cloud pipeline that delivers to OnCall AI, which then orchestrates specialist responses. This separation ensures event-driven workflows receive priority routing without competing with high-volume telemetry streams.
By anchoring both connector types to MCP, Edge Delta maintains protocol consistency even as data patterns differ. Teammates interact with streaming and event sources through the same tool invocation primitives, resource URIs, and governance boundaries. Operations teams reason about one integration model rather than learning distinct patterns for different connector classes.
Why MCP Matters for AI Operations
Operational AI has to be reproducible as well as clever. MCP makes the boundary explicit: the conversational layer asks for capabilities; systems of record decide how to fulfill them. That separation means the same investigation can run against different back ends so long as they present compatible tools and resources, and it means you can rotate models (or combine them) without rewriting integrations. The result is a style of work where answers point at evidence and actions carry their own provenance, which is exactly what audit and post‑incident review require.
Enabling Vendor-Neutral Operations
Organizations resist operational platforms that enforce vendor lock-in through proprietary integrations. When an AI system hard-codes dependencies on specific observability backends, incident management tools, or cloud platforms, switching providers requires re-architecting workflows and losing operational continuity. This coupling constrains technology choices and creates switching costs that persist long after initial adoption decisions.
MCP’s abstraction layer preserves vendor neutrality by decoupling teammates from implementation details. If an organization migrates from Datadog to another observability platform, teammates continue functioning as long as an MCP server exposes compatible tools—log search, metric queries, dashboard access. The conversational layer remains unchanged; only the server implementation shifts. Similarly, switching from GitHub to GitLab, or from PagerDuty to another incident platform, requires updating the backing MCP server while leaving teammate prompts, orchestration logic, and approval workflows intact.
This architecture also supports multi-vendor environments where different teams standardize on different tools. The platform team might use AWS while application teams prefer Azure or GCP. SREs might rely on PagerDuty while the security team uses a different alerting system. Teammates discover and invoke tools from all connected MCP servers, correlating signals across heterogeneous infrastructure without requiring universal platform adoption.
The same abstraction protects against vendor API changes. When a SaaS provider modifies endpoints, authentication models, or response schemas, Edge Delta updates the corresponding MCP server without touching teammate configurations. Organizations avoid the cascading updates that plague tightly coupled systems, where API changes propagate through multiple layers requiring coordinated redeployment.
Data Access Patterns and Strategic Integration Questions
AI teammates require access to the operational data they analyze and act upon. This raises architectural decisions about where data resides and how teammates retrieve it. Two patterns emerge:
Direct MCP access to vendor systems: Teammates invoke tools that query vendor APIs directly—searching Datadog logs, reading Splunk dashboards, or fetching Elastic metrics. This approach minimizes data movement and preserves vendor-specific features, but introduces dependencies on vendor API availability, rate limits, and schema stability. Organizations maintain multiple authentication paths and must coordinate updates when vendor contracts change.
Centralized data access through Edge Delta: Teammates query telemetry that flows through Edge Delta pipelines and persists in Edge Delta’s observability backend. Connectors ingest from original sources, processors apply transformations and enrichment, and data lands in a unified schema that teammates access through the Edge Delta MCP connector. This pattern enables consistent querying regardless of original source, applies uniform governance controls, and insulates teammates from vendor API volatility. However, it requires data duplication if organizations also maintain vendor backends, and introduces dependency on Edge Delta infrastructure.
The transcript reveals this tension explicitly: customers ask whether they can continue using Datadog, Elastic, or Dynatrace as primary observability platforms while leveraging AI teammates. The strategic question becomes whether Edge Delta should support both patterns or converge on the centralized model. Supporting vendor-direct access through their MCP servers (where available) simplifies onboarding but fragments data architecture. Requiring data flow through Edge Delta pipelines consolidates governance and schema consistency but increases migration friction.
Current architecture requires telemetry to flow through Edge Delta pipelines for analysis by specialized teammates, establishing the centralized pattern as the default. Event connectors for services like PagerDuty, GitHub, and Slack follow the direct access pattern, invoking vendor APIs through MCP for actions like creating tickets or posting messages. This hybrid approach balances comprehensive telemetry analysis against pragmatic integration with external workflow systems.
How MCP Powers Edge Delta’s AI Team
Within Edge Delta, teammates use MCP to discover context, ground their explanations, and leave a navigable trail of what happened. The connector catalog shows up as a set of MCP endpoints; a teammate chooses sources based on the question at hand rather than on hard‑coded rules. Conversation state keeps handles to the actual artifacts consulted (the log pattern, the anomaly cluster, the ticket) so a follow‑up can reference the same object rather than re‑quote large payloads. When a runbook is in play, the sequence of calls that produced inputs becomes part of the record; higher‑risk steps package the original request, the derived insight, and a proposed change for approval in Slack or the Edge Delta UI, keeping humans in the loop without losing context.
Paths to MCP Connectivity in Edge Delta
Edge Delta supports two complementary approaches:
Edge Delta MCP Connector. This first‑party connector exposes telemetry pipelines, dashboards, and operational data to the AI Team through standardized MCP tools. It respects masking, RBAC, and retention policies defined in your organization, ensuring that teammates see only sanctioned data while still being able to carry out rich investigations. Activity logs in the AI Team workspace capture each request and response for review and compliance.
Custom Remote MCP Server Connector. When your environment includes proprietary systems, legacy data stores, or vendor APIs without a native Edge Delta connector, you can point the AI Team at any MCP‑compliant server you control. The AI Team then invokes the tools exposed by that server using natural language, without users needing to know the underlying API shapes.
Edge Delta includes a broad catalog of event connectors used by the AI Team to monitor, correlate, and act. Some connectors are implemented natively, while others are integrated through MCP. The catalog includes (not exhaustive): Atlassian, AWS, CircleCI, Databricks, Edge Delta MCP, Custom Remote MCP, GitHub, Jenkins, LaunchDarkly, Linear, Microsoft Teams, PagerDuty, Sentry, and Slack. The common protocol surface lets teammates move fluidly between these systems during an investigation, while preserving a consistent audit trail of what was accessed and why.
Example Scenarios with the Custom Remote MCP
Custom servers often wrap internal CRMs, ticketing layers, legacy mainframes, or vendor APIs—translating proprietary interfaces into clean MCP operations so teammates can ask natural questions and receive well‑typed results.
Common integration patterns for systems not covered by Edge Delta’s native event connectors include:
- Internal tools and repositories: Connect to private GitLab instances, Bitbucket servers, or proprietary version control systems to query commit history, review internal code changes, or analyze deployment patterns
- Databases and data platforms: Expose PostgreSQL, SQLite, Redis, or time-series databases through read-only or controlled-write interfaces, enabling natural-language queries that translate to SQL or database-specific commands
- Cloud infrastructure: Query Azure resources or Google Cloud Platform components to retrieve configuration, check service health, or gather deployment metadata
- Document and knowledge systems: Integrate internal wikis, document repositories, or knowledge bases that aren’t covered by existing connectors
- Business systems: Connect to internal CRMs, ERP systems, payment platforms, or financial APIs to query customer data, retrieve transaction history, or summarize analytics
- Legacy and proprietary systems: Bridge mainframe applications, custom databases, or homegrown tools that lack modern APIs
The MCP servers repository provides reference implementations demonstrating these patterns, including filesystem access with security controls, Git repository operations, and knowledge graph storage systems.
Example Scenarios with the Edge Delta MCP Connector
The Edge Delta MCP Connector enables teammates to interact naturally with observability data and pipeline configuration:
Incident Investigation
Incident work benefits from a deliberate arc: enumerate relevant sources, run targeted searches, pull representative traces, and compare today’s picture with historical baselines. During an investigation, a teammate might:
- Search logs across multiple pipelines using natural language queries
- Retrieve and explain anomaly patterns detected by Edge Delta processors
- Fetch metric trends and correlate them with recent deployments
- Compare current error rates against historical baselines
- Generate incident summaries that cite specific log patterns and metric data
Dashboard Analysis
Teammates can read dashboard definitions to explain what each widget measures and fetch current values to give a live narrative without forcing people into the UI. For example, asking “What’s the health of our API services?” might trigger the teammate to query relevant dashboards, interpret metric trends, and provide context about whether observed patterns are normal for the time of day or deployment cycle.
Pipeline Configuration
Configuration-centric conversations follow the same seam. A teammate might retrieve a pipeline configuration, propose changes such as adding a new source, and deploy the update, all subject to approval policies. Where change control is stricter, deployment tools can be configured to require human approval rather than execute immediately. For example, a teammate could review current pipeline configurations, identify missing sources, add a source node, and deploy the updated configuration with a clear explanation of who requested the change and why. See the Edge Delta MCP Connector for the specific tools available today.
Integration Patterns
Teams typically adopt MCP along one or more patterns, depending on their organizational structure, security requirements, and operational workflows.
Single‑Domain Server
A product area (observability, commerce, risk) is represented by one server that contains the tools and resources for that domain. This limits blast radius and keeps permissioning straightforward.
This pattern works well when domains have distinct ownership, compliance boundaries, or rate limits. For example, your observability team might maintain an MCP server exposing log search, metric queries, and trace retrieval, while your security team operates a separate server for vulnerability scans, audit logs, and access reviews. Each server can evolve independently, and permissions map cleanly to existing RBAC structures. When an incident crosses domains, teammates can invoke tools from multiple servers in sequence while maintaining clear attribution of which system provided which insight.
Aggregator Server
A single server proxies several back ends and presents a unified surface. This is useful when conversations frequently require cross‑system correlation, though it shifts more responsibility for routing and failure handling to the server.
Aggregators simplify the client experience by hiding heterogeneity: instead of teaching teammates about five different inventory APIs, you expose one get_inventory tool that internally fans out to regional databases, reconciles results, and returns a consolidated view. The trade-off is operational complexity. The aggregator becomes a critical path and must handle partial failures gracefully. Teams often build aggregators when they want to enforce a common schema across legacy and modern systems, or when they need to apply cross-cutting concerns like caching, rate limiting, or audit logging in one place.
Per‑Team Servers
Each team curates its own server with curated tools and prompts that reflect how that team works. The AI client can connect to many servers at once and plan across them.
This pattern supports organizational autonomy: the SRE team exposes runbook tools for restarting services and checking health endpoints, the data engineering team provides tools for querying data lakes and triggering pipelines, and the customer success team maintains tools for looking up account history and creating support tickets. Teammates discover all available servers and select the relevant ones based on the question being asked. Because each team controls its own server lifecycle, they can iterate on tool design, add domain-specific resources, and retire obsolete operations without cross-team coordination. This decentralization scales well but requires governance to prevent tool proliferation and naming collisions.
Adapter Servers for Non‑MCP Systems
Where direct MCP support does not exist, lightweight adapters map vendor APIs or legacy interfaces into MCP operations. This approach provides immediate utility without waiting on vendor roadmaps.
Adapter servers are translation layers: they accept MCP tool calls, transform them into the vendor’s native format (REST, GraphQL, SOAP, or even terminal commands), and package responses back into structured MCP results. For example, you might wrap a proprietary ticketing system’s API so teammates can search tickets, update priorities, and add comments using natural language, even though the vendor has no MCP support. Adapters also work for internal systems that predate modern API design—mainframes, batch job schedulers, or custom databases—allowing operational AI to reach parts of your infrastructure that would otherwise remain invisible. The adapter pattern keeps integration logic isolated and testable, and you can replace the adapter with a native connector later without changing how teammates interact with the system.
Composable Conversations
Because servers expose stable resource handles, conversations can pass those handles between teammates or across steps in a runbook, maintaining continuity without copying large payloads into prompts.
Resource handles act as lightweight pointers: instead of embedding a full configuration document or a hundred-line log sample in a prompt, a teammate retrieves a handle (using whatever URI scheme the server defines—config://, data://, file://, etc.) and passes it to the next step. Another teammate can dereference that handle to fetch the latest data, compare it with a different time range, or link it to a ticket. This keeps context windows manageable and ensures teammates always work with fresh data rather than stale snapshots. Composable conversations also enable workflows where one teammate investigates an anomaly, hands off a resource handle to a specialist for deeper analysis, and then a third teammate uses the same handle to generate an incident summary—all without re-querying the underlying system or losing track of what was examined.
Governance and Observability
Governance is part of the envelope rather than an afterthought. Enforcement attaches to the client and server boundaries—the MCP endpoints—rather than the provider layer, so controls apply uniformly regardless of what systems sit behind each server. Every exchange records request and response payloads with timestamps and initiating identity, which makes post‑incident review and periodic audits concrete rather than forensic. Edge Delta enforces residency controls for data it processes and returns via MCP; provider-side residency depends on the underlying system’s configuration. Masking is applied before anything crosses a boundary. When a connector is unavailable, teammates don’t guess. They return a degraded but explicit response that cites the missing resource so humans can intervene without chasing ambiguous failures.
Design Considerations and Limits
MCP encourages small, explicit contracts, which makes planning easier but shifts attention to latency and context size. Tools should return structured results that can be paged or summarized before entering a prompt; long‑running work ought to yield handles rather than oversized payloads. Idempotency and clear error semantics make retries predictable; authentication belongs at the server boundary so tokens can rotate without redeploying clients. Version tool schemas and resource representations so capability changes are detectable, and prefer additive evolution over breaking changes. These habits keep conversations resilient even as systems behind the seam move at different speeds.
Frequently Asked Questions
Is MCP tied to a particular LLM? No. MCP specifies how a client and server exchange structured operations and documents; it does not constrain which model generates or interprets the surrounding conversation.
How many MCP servers can a conversation use? As many as needed. The client can maintain several connections and choose per step which server to call, making cross‑system correlation a first‑class pattern.
What happens if a server is slow or down? The AI Team degrades gracefully, citing the missing resource and continuing with available context so humans know what could not be retrieved.
How does MCP relate to function calling? Function calling enables LLMs to generate structured outputs describing function invocations. MCP standardizes this pattern by defining a protocol for discovering, describing, and executing tools (functions) across different systems. While function calling focuses on the LLM’s ability to produce structured tool calls, MCP provides the infrastructure for advertising available tools, validating inputs, and returning results in a consistent way across multiple servers.
Further Reading
- Model Context Protocol Specification - Official MCP documentation and architecture overview
- MCP Specification (Latest) - Detailed protocol specification
- Function Calling with LLMs - Guest article by Kiran Prakash on Martin Fowler’s site