Filebeat Source
Configure the Filebeat source to receive log data from Filebeat, Logstash, Vector, and other Elastic Beats agents using the Elasticsearch Bulk API protocol.
20 minute read
Overview
The Filebeat source node receives log data using the Elasticsearch Bulk API protocol.
Use the configuration wizard below to generate a starter YAML configuration.
This allows Edge Delta to act as an Elasticsearch-compatible endpoint, accepting data from Filebeat, Logstash, Vector, and other tools in the Elastic ecosystem that send data using the Elasticsearch protocol.
This node was previously named “Elasticsearch API” and was renamed in v2.11.0 to better reflect its primary use case of receiving data from Filebeat agents.
The source listens on an HTTP endpoint and processes incoming data in the Elasticsearch bulk format, making it compatible with:
- Elastic Beats family: Filebeat, Metricbeat, Heartbeat, Auditbeat, Packetbeat
- Logstash: Using the Elasticsearch output plugin
- Vector: Using the Elasticsearch sink
- Elastic Agent: Direct integration with Elasticsearch-compatible endpoints
This node requires Edge Delta agent version v2.7.0 or higher.
AI Team: Configure this source using the Filebeat connector for streamlined setup in AI Team.
- outgoing_data_types: log
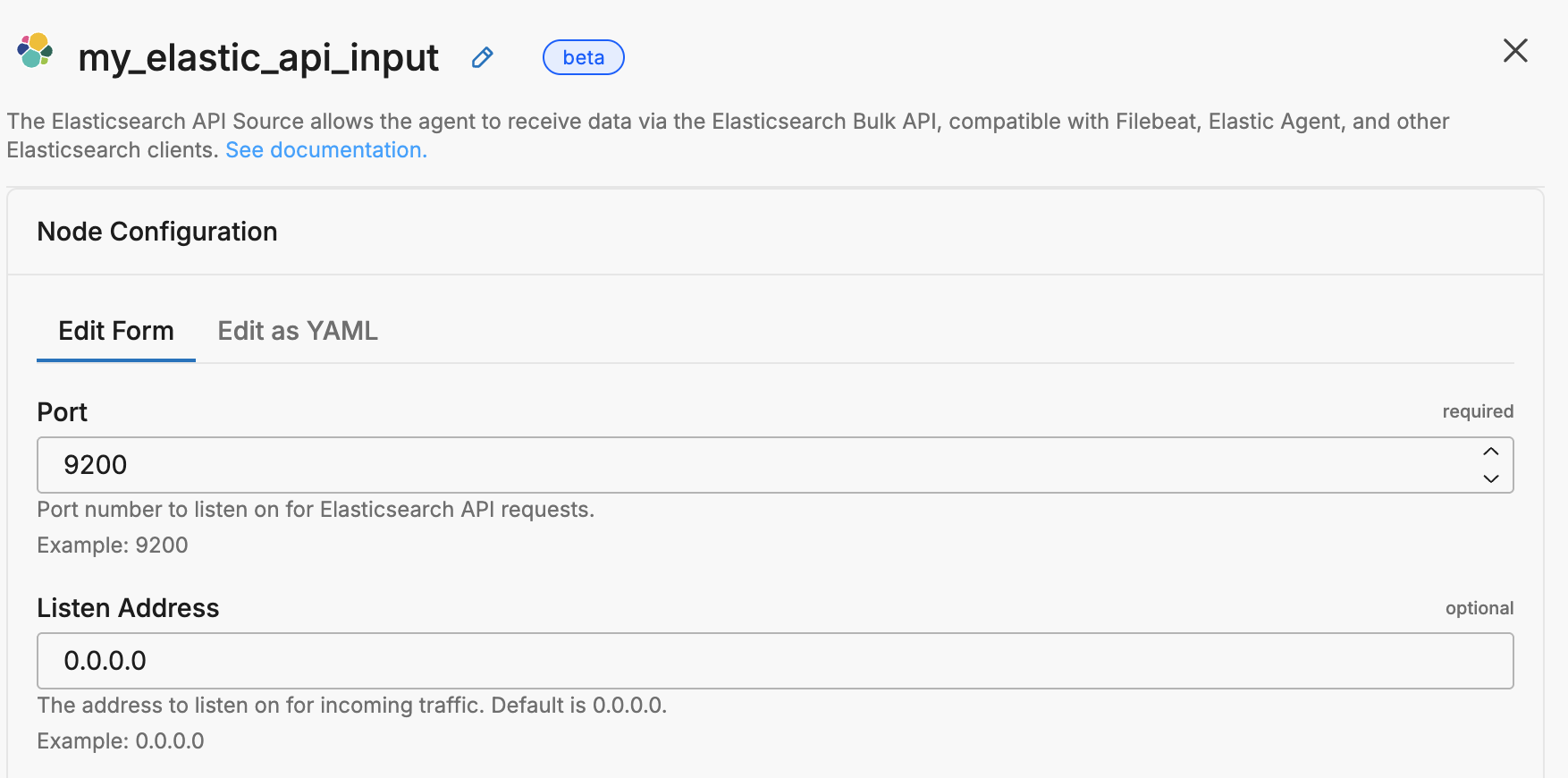
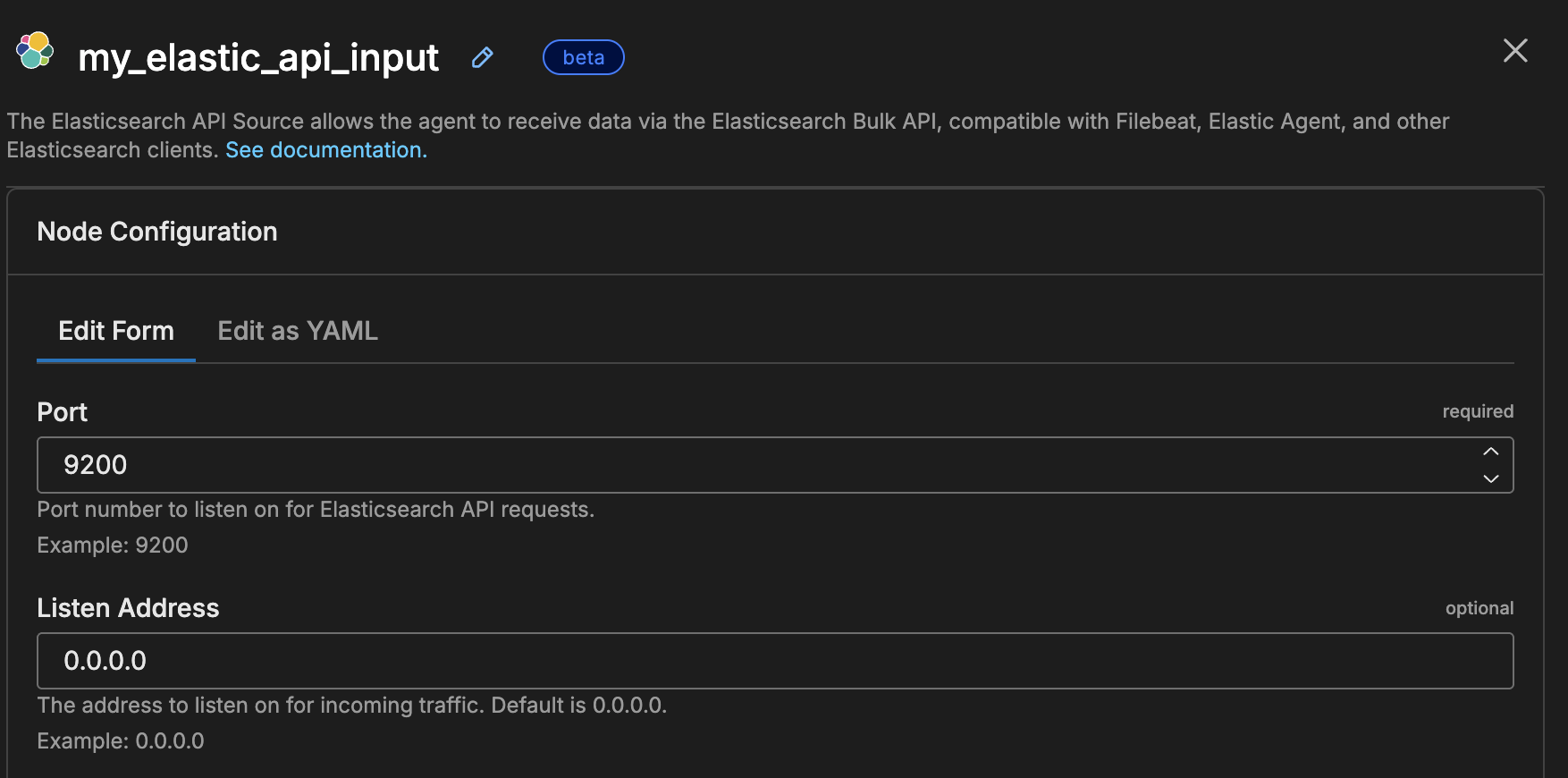
Example Configuration
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
listen: "0.0.0.0"
Filebeat Configuration Example
To configure Filebeat to send data to the Edge Delta Elasticsearch API input, use the Elasticsearch output in your filebeat.yml:
filebeat.inputs:
- type: container
paths:
- /var/log/containers/*.log
# Output to Edge Delta Elasticsearch API
output.elasticsearch:
hosts: ["http://localhost:9200"]
protocol: "http"
# Index name pattern
index: "filebeat-%{+yyyy.MM.dd}"
# Bulk settings for performance tuning
bulk_max_size: 50
worker: 1
compression_level: 0
# Connection settings
timeout: 30
max_retries: 3
# Disable Elasticsearch-specific features
setup.template.enabled: false
setup.ilm.enabled: false
Important: Since Edge Delta is not a full Elasticsearch instance, disable template and ILM (Index Lifecycle Management) features as shown above.
Logstash Configuration Example
To configure Logstash to send data to the Edge Delta Elasticsearch API input, use the Elasticsearch output in your Logstash pipeline:
output {
elasticsearch {
hosts => ["http://localhost:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
Vector Configuration Example
To configure Vector to send data to the Edge Delta Elasticsearch API input:
[sinks.edge_delta]
type = "elasticsearch"
inputs = ["my_source"]
endpoint = "http://localhost:9200"
mode = "bulk"
Required Parameters
name
A descriptive name for the node. This is the name that will appear in pipeline builder and you can reference this node in the YAML using the name. It must be unique across all nodes. It is a YAML list element so it begins with a - and a space followed by the string. It is a required parameter for all nodes.
nodes:
- name: <node name>
type: <node type>
type: elastic_api_input
The type parameter specifies the type of node being configured. It is specified as a string from a closed list of node types. It is a required parameter.
nodes:
- name: <node name>
type: <node type>
port
The port parameter specifies the TCP port number that the Elasticsearch API input should listen on. Port 9200 is the standard Elasticsearch port and provides compatibility with default Elastic tooling configurations. It is specified as an integer between 1 and 65535 and is required.
Default: 9200
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
Optional Parameters
disabled
The disabled parameter disables the node in the pipeline. When set to true, the agent ignores the node at startup. You can toggle nodes on or off in the pipeline builder. It is specified as a boolean, defaults to false, and is optional.
nodes:
- name: <node name>
type: <node type>
disabled: true
listen
The listen parameter specifies the IP address to bind to for listening on incoming traffic. Use 0.0.0.0 to listen on all network interfaces, or specify a specific IP address to restrict access. It is specified as a string and is optional.
Default: 0.0.0.0
Examples:
0.0.0.0- Listen on all network interfaces192.168.1.100- Listen only on specific interface127.0.0.1- Localhost only (for testing)
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
listen: "0.0.0.0"
endpoint
The endpoint parameter specifies the Elasticsearch Bulk API endpoint path. This allows customization of the API path that clients connect to. It is specified as a string and is optional.
Default: /_bulk
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
endpoint: "/_bulk"
show_originating_ip
The show_originating_ip parameter determines whether to include the client’s IP address in the ingested data. When enabled, the originating IP address is captured as metadata, useful for tracking the source of logs and security analysis. It is specified as a boolean and is optional.
Default: false
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
show_originating_ip: true
capture_request_headers
The capture_request_headers parameter determines whether to capture and include HTTP request headers in the ingested data. When enabled, HTTP headers from incoming requests are preserved as metadata. It is specified as a boolean and is optional.
Default: false
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
capture_request_headers: true
enable_health_check
The enable_health_check parameter controls whether the health check endpoint is available at /_cluster/health. This endpoint allows monitoring tools to verify that the Elasticsearch API input is operational and compatible with Elasticsearch health check mechanisms. It is specified as a boolean and is optional.
Default: true
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
enable_health_check: true
active_request_limit
The active_request_limit parameter sets the maximum number of concurrent requests the node will handle simultaneously. This helps prevent resource exhaustion under high load. It is specified as an integer and is optional.
Default: 256
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
active_request_limit: 512
api_version
The api_version parameter specifies which Elasticsearch API version to emulate. This version is reported in health check responses and helps ensure compatibility with clients that check API version compatibility. It is specified as a string and is optional.
Default: 8.3.2
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
api_version: "8.3.2"
custom_api_version_response
The custom_api_version_response parameter allows you to provide a custom JSON response for the Elasticsearch API version endpoint. This is useful when you need to match a specific Elasticsearch response format for compatibility with particular clients. It is specified as a multi-line text (JSON) and is optional.
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
custom_api_version_response: |
{
"name": "edge-delta",
"cluster_name": "edge-delta-cluster",
"version": {
"number": "8.3.2"
}
}
authentication
The authentication configuration block enables HTTP authentication for incoming requests. You can configure either Basic authentication (username/password) or Bearer token authentication. It is an optional parameter that contains sub-parameters.
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
authentication:
<authentication options>
strategy
The strategy parameter specifies which HTTP authentication method to use. It is optional.
Available options:
Basic- Username and password authenticationBearer- Token-based authentication
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
authentication:
strategy: Basic
username
The username parameter specifies the username for Basic authentication. This parameter is required when using Basic authentication strategy. It is optional.
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
authentication:
strategy: Basic
username: "elastic"
password: "changeme"
password
The password parameter specifies the password for Basic authentication. This parameter is required when using Basic authentication strategy. It is optional.
This field supports secret references for secure credential management. Instead of hardcoding sensitive values, you can reference a secret configured in your pipeline.
To use a secret in the GUI:
- Create a secret in your pipeline’s Settings > Secrets section (see Secrets)
- In this field, select the secret name from the dropdown list that appears
To use a secret in YAML:
Reference it using the syntax: '{{ SECRET secret-name }}'
Example:
field_name: '{{ SECRET my-credential }}'
Note: The secret reference must be enclosed in single quotes when using YAML. Secret values are encrypted at rest and resolved at runtime, ensuring no plaintext credentials appear in logs or API responses.
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
authentication:
strategy: Basic
username: "elastic"
password: "changeme"
secret
The secret parameter specifies the bearer token for Bearer authentication. This parameter is required when using Bearer authentication strategy. It is optional.
This field supports secret references for secure credential management. Instead of hardcoding sensitive values, you can reference a secret configured in your pipeline.
To use a secret in the GUI:
- Create a secret in your pipeline’s Settings > Secrets section (see Secrets)
- In this field, select the secret name from the dropdown list that appears
To use a secret in YAML:
Reference it using the syntax: '{{ SECRET secret-name }}'
Example:
field_name: '{{ SECRET my-credential }}'
Note: The secret reference must be enclosed in single quotes when using YAML. Secret values are encrypted at rest and resolved at runtime, ensuring no plaintext credentials appear in logs or API responses.
nodes:
- name: my_elastic_api_input
type: elastic_api_input
port: 9200
authentication:
strategy: Bearer
secret: "my-secret-token-12345"
source_metadata
This option is used to define which detected resources and attributes to add to each data item as it is ingested by Edge Delta. You can select:
- Required Only: This option includes the minimum required resources and attributes for Edge Delta to operate.
- Default: This option includes the required resources and attributes plus those selected by Edge Delta
- High: This option includes the required resources and attributes along with a larger selection of common optional fields.
- Custom: With this option selected, you can choose which attributes and resources to include. The required fields are selected by default and can’t be unchecked.
Based on your selection in the GUI, the source_metadata YAML is populated as two dictionaries (resource_attributes and attributes) with Boolean values.
See Choose Data Item Metadata for more information on selecting metadata.
rate_limit
The rate_limit parameter enables you to control data ingestion based on system resource usage. This advanced setting helps prevent source nodes from overwhelming the agent by automatically throttling or stopping data collection when CPU or memory thresholds are exceeded.
Use rate limiting to prevent runaway log collection from overwhelming the agent in high-volume sources, protect agent stability in resource-constrained environments with limited CPU/memory, automatically throttle during bursty traffic patterns, and ensure fair resource allocation across source nodes in multi-tenant deployments.
When rate limiting triggers, pull-based sources (File, S3, HTTP Pull) stop fetching new data, push-based sources (HTTP, TCP, UDP, OTLP) reject incoming data, and stream-based sources (Kafka, Pub/Sub) pause consumption. Rate limiting operates at the source node level, where each source with rate limiting enabled independently monitors and enforces its own thresholds.
Rate limiting vs backpressure: Rate limiting and backpressure are different mechanisms. Rate limiting controls data ingestion at the source based on CPU or memory thresholds. Backpressure controls data output at the destination when in-memory queues fill up. Backpressure logs such as
backpressure: dataCh at 92% capacitydo not appear when rate limiting triggers, and rate limiting logs do not appear during backpressure events.
Observability: When rate limiting is active in enforce mode, the agent does not produce INFO, WARN, or ERROR level logs. To confirm that rate limiting is triggering, check the source node’s Bytes I/O metrics in the Edge Delta app for gaps or drops that coincide with expected throttling periods.
Configuration Steps:
- Click Add New in the Rate Limit section
- Click Add New for Evaluation Policy
- Select Policy Type:
- CPU Usage: Monitors CPU consumption and rate limits when usage exceeds defined thresholds. Use for CPU-intensive sources like file parsing or complex transformations.
- Memory Usage: Monitors memory consumption and rate limits when usage exceeds defined thresholds. Use for memory-intensive sources like large message buffers or caching.
- AND (composite): Combines multiple sub-policies with AND logic. All sub-policies must be true simultaneously to trigger rate limiting. Use when you want conservative rate limiting (both CPU and memory must be high).
- OR (composite): Combines multiple sub-policies with OR logic. Any sub-policy can trigger rate limiting. Use when you want aggressive rate limiting (either CPU or memory being high triggers).
- Select Evaluation Mode. Choose how the policy behaves when thresholds are exceeded:
- Enforce (default): Actively applies rate limiting when thresholds are met. Pull-based sources (File, S3, HTTP Pull) stop fetching new data, push-based sources (HTTP, TCP, UDP, OTLP) reject incoming data, and stream-based sources (Kafka, Pub/Sub) pause consumption. Use in production to protect agent resources.
- Monitor: Logs when rate limiting would occur without actually limiting data flow. Use for testing thresholds before enforcing them in production.
- Passthrough: Disables rate limiting entirely while keeping the configuration in place. Use to temporarily disable rate limiting without removing configuration.
- Set Absolute Limits and Relative Limits (for CPU Usage and Memory Usage policies)
Note: If you specify both absolute and relative limits, the system evaluates both conditions and rate limiting triggers when either condition is met (OR logic). For example, if you set absolute limit to
1.0CPU cores and relative limit to50%, rate limiting triggers when the source uses either 1 full core OR 50% of available CPU, whichever happens first.
For CPU Absolute Limits: Enter value in full core units:
0.1= one-tenth of a CPU core0.5= half a CPU core1.0= one full CPU core2.0= two full CPU cores
For CPU Relative Limits: Enter percentage of total available CPU (0-100):
50= 50% of available CPU75= 75% of available CPU85= 85% of available CPU
For Memory Absolute Limits: Enter value in bytes
104857600= 100Mi (100 × 1024 × 1024)536870912= 512Mi (512 × 1024 × 1024)1073741824= 1Gi (1 × 1024 × 1024 × 1024)
For Memory Relative Limits: Enter percentage of total available memory (0-100)
60= 60% of available memory75= 75% of available memory80= 80% of available memory
- Set Refresh Interval (for CPU Usage and Memory Usage policies). Specify how frequently the system checks resource usage:
- Recommended Values:
10sto30sfor most use cases5sto10sfor high-volume sources requiring quick response1mor higher for stable, low-volume sources
The system fetches current CPU/memory usage at the specified refresh interval and uses that value for evaluation until the next refresh. Shorter intervals provide more responsive rate limiting but incur slightly higher overhead, while longer intervals are more efficient but slower to react to sudden resource spikes.
The GUI generates YAML as follows:
# Simple CPU-based rate limiting
nodes:
- name: <node name>
type: <node type>
rate_limit:
evaluation_policy:
policy_type: cpu_usage
evaluation_mode: enforce
absolute_limit: 0.5 # Limit to half a CPU core
refresh_interval: 10s
# Simple memory-based rate limiting
nodes:
- name: <node name>
type: <node type>
rate_limit:
evaluation_policy:
policy_type: memory_usage
evaluation_mode: enforce
absolute_limit: 536870912 # 512Mi in bytes
refresh_interval: 30s
Composite Policies (AND / OR)
When using AND or OR policy types, you define sub-policies instead of limits. Sub-policies must be siblings (at the same level)—do not nest sub-policies within other sub-policies. Each sub-policy is independently evaluated, and the parent policy’s evaluation mode applies to the composite result.
- AND Logic: All sub-policies must evaluate to true at the same time to trigger rate limiting. Use when you want conservative rate limiting (limit only when CPU AND memory are both high).
- OR Logic: Any sub-policy evaluating to true triggers rate limiting. Use when you want aggressive protection (limit when either CPU OR memory is high).
Configuration Steps:
- Select AND (composite) or OR (composite) as the Policy Type
- Choose the Evaluation Mode (typically Enforce)
- Click Add New under Sub-Policies to add the first condition
- Configure the first sub-policy by selecting policy type (CPU Usage or Memory Usage), selecting evaluation mode, setting absolute and/or relative limits, and setting refresh interval
- In the parent policy (not within the child), click Add New again to add a sibling sub-policy
- Configure additional sub-policies following the same pattern
The GUI generates YAML as follows:
# AND composite policy - both CPU AND memory must exceed limits
nodes:
- name: <node name>
type: <node type>
rate_limit:
evaluation_policy:
policy_type: and
evaluation_mode: enforce
sub_policies:
# First sub-policy (sibling)
- policy_type: cpu_usage
evaluation_mode: enforce
absolute_limit: 0.75 # Limit to 75% of one core
refresh_interval: 15s
# Second sub-policy (sibling)
- policy_type: memory_usage
evaluation_mode: enforce
absolute_limit: 1073741824 # 1Gi in bytes
refresh_interval: 15s
# OR composite policy - either CPU OR memory can trigger
nodes:
- name: <node name>
type: <node type>
rate_limit:
evaluation_policy:
policy_type: or
evaluation_mode: enforce
sub_policies:
- policy_type: cpu_usage
evaluation_mode: enforce
relative_limit: 85 # 85% of available CPU
refresh_interval: 20s
- policy_type: memory_usage
evaluation_mode: enforce
relative_limit: 80 # 80% of available memory
refresh_interval: 20s
# Monitor mode for testing thresholds
nodes:
- name: <node name>
type: <node type>
rate_limit:
evaluation_policy:
policy_type: memory_usage
evaluation_mode: monitor # Only logs, doesn't limit
relative_limit: 70 # Test at 70% before enforcing
refresh_interval: 30s
tls
Configure TLS settings for secure connections to this source. TLS is optional and typically used when the source node needs to accept encrypted connections or perform mutual TLS authentication with clients.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
<tls options>
CA Certificate File
Specifies the absolute path to a single CA (Certificate Authority) certificate file used to verify client certificates during mutual TLS authentication. This file contains the trusted CA certificate that signed the client certificates. Use this when you have a single CA certificate. (YAML parameter: ca_file)
When to use: Required when client_auth_type is set to verifyclientcertifgiven or requireandverifyclientcert. Choose either ca_file or ca_path, not both.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
ca_file: /certs/ca.pem
client_auth_type: requireandverifyclientcert
CA Certificate Path
Specifies a directory path containing one or more CA certificate files for client certificate verification. Use this when you need to trust multiple CAs or when managing CA certificates across multiple files. All certificate files in the directory will be loaded. (YAML parameter: ca_path)
When to use: Alternative to ca_file when you have multiple CA certificates. Required when client_auth_type is set to verifyclientcertifgiven or requireandverifyclientcert. Choose either ca_file or ca_path, not both.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
ca_path: /certs/ca-certificates/
client_auth_type: requireandverifyclientcert
Certificate File
Path to the server certificate file (public key) that will be presented to connecting clients during the TLS handshake. This certificate identifies the server and must match the private key. The certificate should be in PEM format and can include the full certificate chain. (YAML parameter: crt_file)
When to use: Required for TLS/HTTPS connections. Must be used together with key_file. Obtain this from your certificate authority or generate a self-signed certificate for testing.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
crt_file: /certs/server-cert.pem
key_file: /certs/server-key.pem
Private Key File
Path to the private key file corresponding to the server certificate. This key must match the public key in the certificate file and is used to decrypt communications encrypted with the public key. Keep this file secure and restrict access permissions. (YAML parameter: key_file)
When to use: Required for TLS/HTTPS connections. Must be used together with crt_file. If the key file is encrypted, also specify key_password.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
crt_file: /certs/server-cert.pem
key_file: /certs/server-key.pem
key_password: <password> # Only if key is encrypted
Private Key Password
Password (passphrase) used to decrypt an encrypted private key file. Only needed if your private key file is password-protected. If your key file is unencrypted, omit this parameter. (YAML parameter: key_password)
When to use: Optional. Only required if key_file is encrypted/password-protected. For enhanced security, use encrypted keys in production environments.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
crt_file: /certs/server-cert.pem
key_file: /certs/encrypted-server-key.pem
key_password: mySecurePassword123
Client Authentication Type
Controls how client certificates are requested and validated during the TLS handshake. This setting is specific to server-side TLS and determines the mutual TLS (mTLS) behavior. Use this to enforce certificate-based authentication from connecting clients for enhanced security. (YAML parameter: client_auth_type)
Valid options:
noclientcert- No client certificate is requested; any sent certificates are ignored. Use for standard TLS encryption without client authentication.requestclientcert- Client certificate is requested but not required. Useful for optional client authentication where you want to accept both authenticated and unauthenticated clients.requireanyclientcert- Client must send a certificate, but it is not validated against a CA. Use when you need proof a client has a certificate but don’t need to verify its authenticity.verifyclientcertifgiven- Certificate is requested but not required; if sent, it must be valid and signed by a trusted CA. Balances security with flexibility for mixed client environments.requireandverifyclientcert- Client must send a valid certificate signed by a trusted CA (full mutual TLS). Use for maximum security when all clients can be provisioned with certificates.
Default: noclientcert
When to use: Set to verifyclientcertifgiven or requireandverifyclientcert for secure environments where you need to verify client identity. When using certificate verification options, you must also configure ca_file or ca_path to specify the trusted CA certificates.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
client_auth_type: requireandverifyclientcert
ca_file: /certs/ca.pem # Required for certificate validation
Minimum TLS Version
Minimum TLS protocol version that will be accepted from connecting clients. This enforces a baseline security level by rejecting connections from clients using older, less secure TLS versions. (YAML parameter: min_version)
Available versions:
TLSv1_0- Deprecated, not recommended (security vulnerabilities)TLSv1_1- Deprecated, not recommended (security vulnerabilities)TLSv1_2- Recommended minimum for production (default)TLSv1_3- Most secure, use when all clients support it
Default: TLSv1_2
When to use: Set to TLSv1_2 or higher for production deployments. Only use TLSv1_0 or TLSv1_1 if you must support legacy clients that cannot upgrade, and be aware of the security risks. TLS 1.0 and 1.1 are officially deprecated and should be avoided.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
min_version: TLSv1_2
Maximum TLS Version
Maximum TLS protocol version that will be accepted from connecting clients. This is typically used to restrict newer TLS versions if compatibility issues arise with specific client implementations. (YAML parameter: max_version)
Available versions:
TLSv1_0TLSv1_1TLSv1_2TLSv1_3
When to use: Usually left unset to allow the most secure version available. Only set this if you encounter specific compatibility issues with TLS 1.3 clients, or for testing purposes. In most cases, you should allow the latest TLS version.
YAML Configuration Example:
nodes:
- name: <node name>
type: <source type>
tls:
max_version: TLSv1_3
Configuration Wizard
Use this interactive wizard to generate a starter configuration:
What will send data to this endpoint?
Edge Delta emulates an Elasticsearch endpoint to receive data from these tools.
Test with curl
You can test your Edge Delta Elasticsearch API endpoint using curl to send data in the Elasticsearch bulk format:
# Test with a simple bulk request
curl -X POST "http://localhost:9200/_bulk" \
-H "Content-Type: application/x-ndjson" \
-d $'{"index":{"_index":"test"}}\n{"message":"Hello from Edge Delta","@timestamp":"2024-10-27T12:00:00Z"}\n'
Test health check endpoint
# Check the health endpoint
curl "http://localhost:9200/_cluster/health"
Test with Filebeat
You can use Filebeat in debug mode to test the connection:
# Run Filebeat with debug logging
filebeat -e -d "*"
See Also
- Filebeat Connector - Configure this source using AI Team
- Filebeat Reference - Official Filebeat documentation
- Logstash Elasticsearch Output - Logstash output plugin documentation
- Vector Elasticsearch Sink - Vector sink documentation