Data Tiering
Edge Delta's data tiering strategy routes high-value telemetry to high-cost tools and stores other data efficiently.
2 minute read
Data tiering is a foundational best practice for modern observability. It involves directing high-value telemetry to high-cost destinations where it can drive real-time monitoring, while routing lower-value or long-retention data to cost-effective storage systems.
Rather than sending all logs to a single observability platform, Edge Delta enables you to apply logic within your pipeline to segment data based on its purpose and sensitivity. For example, logs that are required for alerting or real-time dashboards can be routed to tools like Datadog or New Relic, while bulk operational logs or compliance records can be stored in services such as Amazon S3 or Google Cloud Storage.
This approach avoids the tradeoffs of aggressive filtering that may result in lost context or reduced visibility. Instead of dropping data altogether, you can retain it intelligently based on its utility and cost profile. This allows teams to meet compliance needs, support forensic investigations, and keep dashboards fast and relevant without overwhelming backend systems.
Tiering also helps coordinate data delivery across teams. Platform teams can send different slices of the same telemetry to different consumers, tailoring outputs without duplicating ingest or increasing storage costs.
Edge Delta supports this strategy through its flexible routing logic and in-cluster processing. Data can be filtered, shaped, enriched, or redacted close to its source before being routed onward, improving both performance and precision.
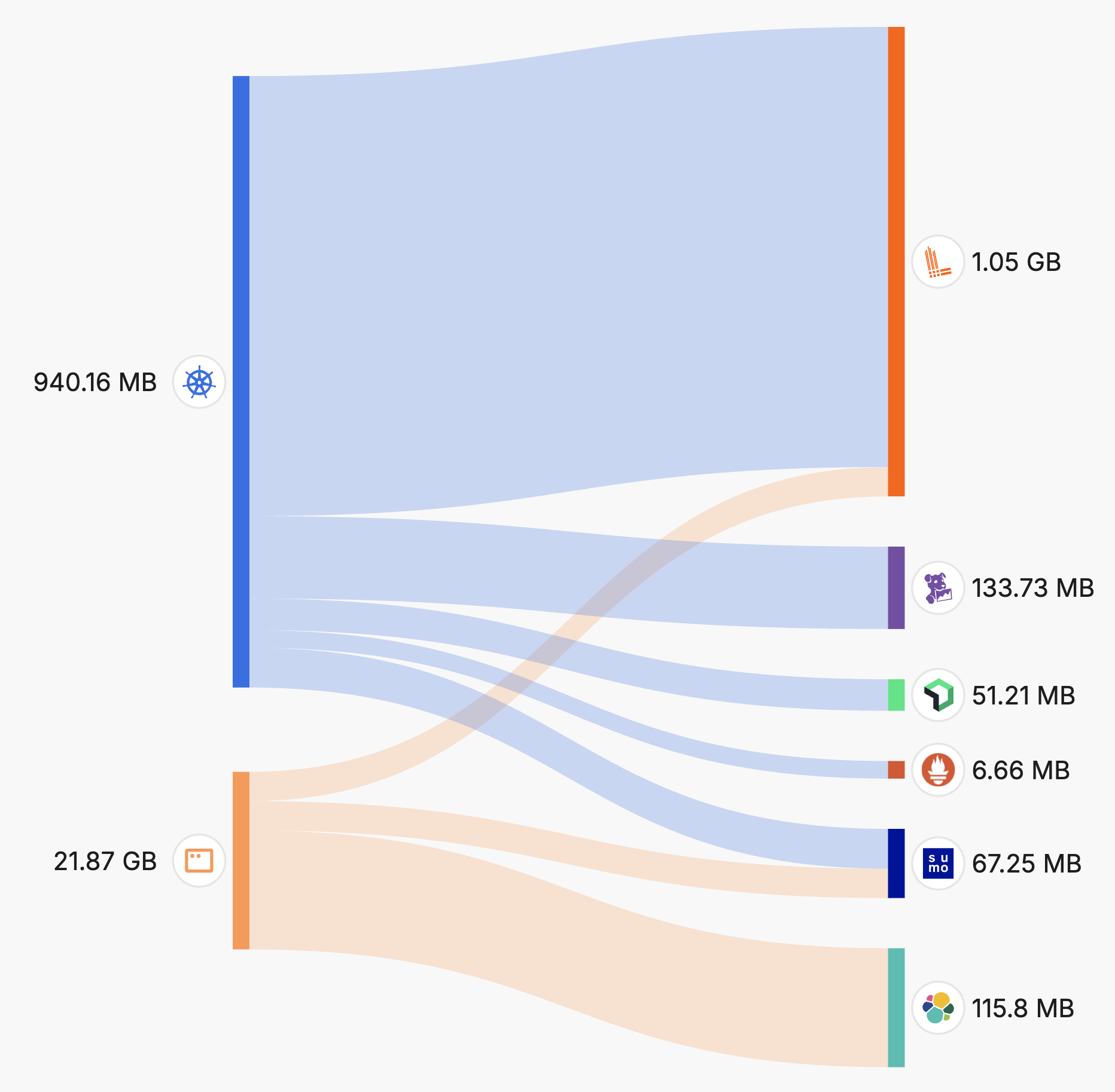
While tiering governs where data goes, in-cluster processing improves how efficiently that decision is made. Edge Delta agents operate directly in your environment, including Kubernetes clusters and other compute platforms. Processing logs near their point of origin reduces the need to send large volumes of data across network boundaries.
This local processing reduces latency, lowers egress costs, and provides faster access to insights. It also aligns with compliance requirements by keeping data within its originating jurisdiction and limits exposure to external systems, improving security posture.
As environments scale, in-cluster processing scales with them. Edge Delta supports dynamic resource allocation, enabling pipelines to grow with demand while maintaining predictable cost and performance characteristics.
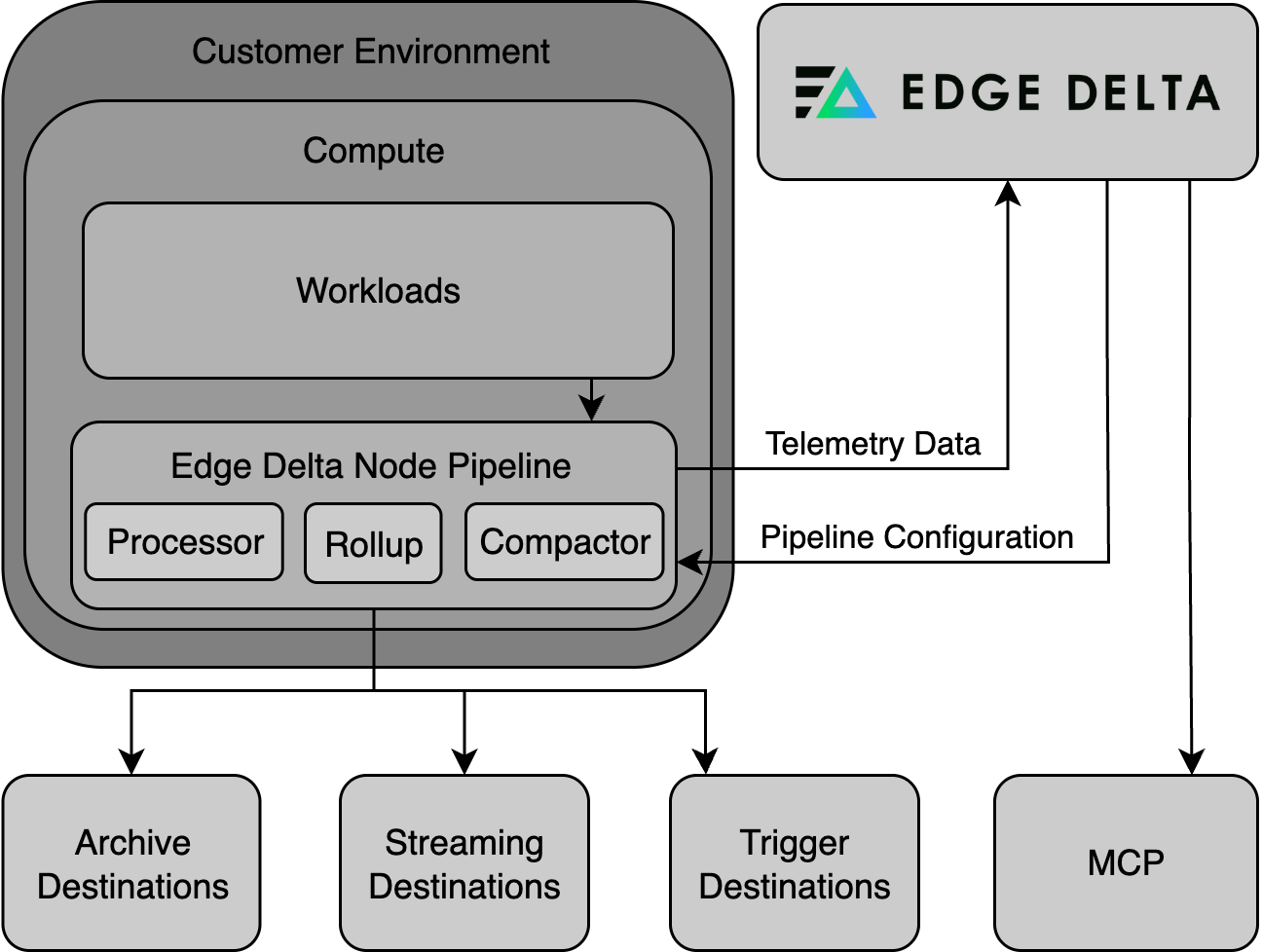
To get started with pipeline-based routing and data tiering:
- Review Destination Options
- Learn about Route Nodes for directing logs by content or attributes
- Explore Conditional Group Processor for rule-based pipeline logic