Edge Delta Parse Grok Processor
12 minute read
Overview
The Grok parsing processor is used to extract structured fields from unstructured log data using Grok patterns. It processes the log body by matching it against a provided Grok pattern, either from the built-in Knowledge Library or a custom pattern. If a match is successful, the extracted fields are stored in the attributes field or custom field. If the destination field, such as attributes already exists, the new fields are merged into it using an upsert strategy. If no match is found (and strict matching is enabled), no new attributes are added.
Grok patterns themselves are human-readable regex macros. The parsing processor uses these patterns to identify meaningful fields like IP addresses, HTTP methods, status codes, etc. You can define your own, select one from the library, or use the AI assistant to generate one from a sample log.
Use the configuration wizard below to generate a starter YAML configuration.
Learn how to configure this in Pipeline Quickstart: Create Structured Attributes.
Example Configuration
Consider this log body:
<14> 1 2025-06-23T10:24:44.849103Z logserver01 monitor 28968 ID167 - New entry
This pattern will can be used to parse the log:
<%{NUMBER:syslog_priority}> %{NUMBER:syslog_version} %{TIMESTAMP_ISO8601:timestamp} %{WORD:hostname} %{WORD:appname} %{NUMBER:pid} %{WORD:log_id} - %{GREEDYDATA:message}
It will create the following structure:
%{NUMBER:syslog_priority}: Extracts the syslog priority number.%{NUMBER:syslog_version}: Captures the syslog version number.%{TIMESTAMP_ISO8601:timestamp}: Captures the ISO 8601 timestamp.%{WORD:hostname}: Captures the hostname.%{WORD:appname}: Captures the application or service name.%{NUMBER:pid}: Captures the process ID.%{WORD:log_id}: Captures the log ID.%{GREEDYDATA:message}: Captures the rest of the log entry as the message.
The processor is configured as follows:
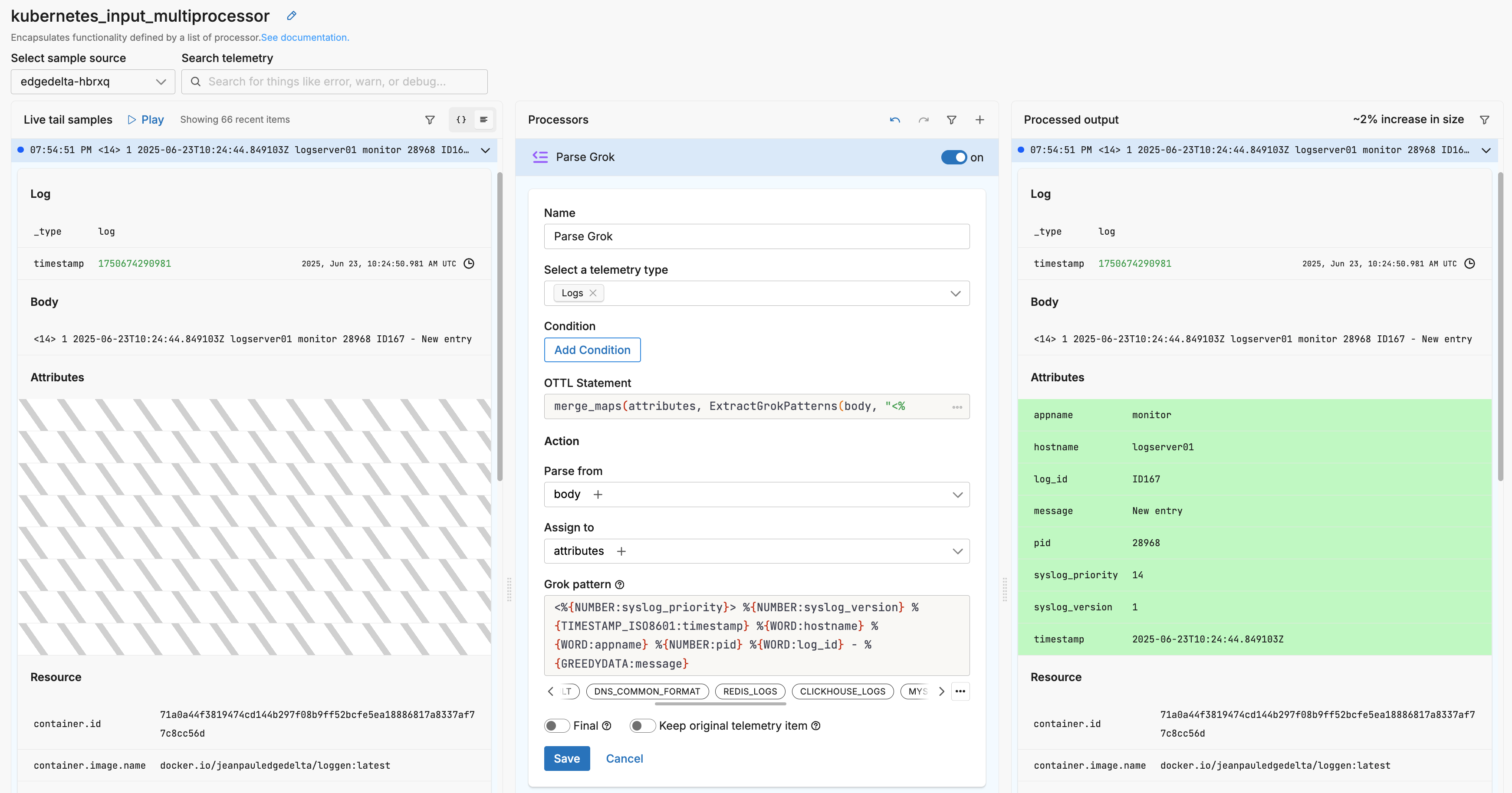
This configuration can be represented with the following YAML
- name: kubernetes_input_multiprocessor
type: sequence
processors:
- type: ottl_transform
metadata: '{"id":"jAV8KAUBPP8WQc1dXREQZ","type":"parse-grok","name":"Parse Grok"}'
data_types:
- log
statements: |-
merge_maps(attributes, ExtractGrokPatterns(body, "<%{NUMBER:syslog_priority}> %{NUMBER:syslog_version} %{TIMESTAMP_ISO8601:timestamp} %{WORD:hostname} %{WORD:appname} %{NUMBER:pid} %{WORD:log_id} - %{GREEDYDATA:message}", true), "upsert") where IsMap(attributes)
set(attributes, ExtractGrokPatterns(body, "<%{NUMBER:syslog_priority}> %{NUMBER:syslog_version} %{TIMESTAMP_ISO8601:timestamp} %{WORD:hostname} %{WORD:appname} %{NUMBER:pid} %{WORD:log_id} - %{GREEDYDATA:message}", true)) where not IsMap(attributes)
From the YAML, you can see the logic applied by the processor:
These two statements ensure that attributes extracted from the log messages are properly incorporated into existing data:
- If attributes is a map, it is enhanced with the new data using the merge_maps function to ensure data integrity through “upsert” operations.
- If attributes is not a map, it is completely replaced by the new data map obtained from the log content, ensuring that the attributes are consistently structured following the Grok extraction.
The output data items has parsed the body using the named captures:
{
"_type": "log",
"timestamp": 1750674290981,
"body": "<14> 1 2025-06-23T10:24:44.849103Z logserver01 monitor 28968 ID167 - New entry",
"resource": {
...
},
"attributes": {
"appname": "monitor",
"hostname": "logserver01",
"log_id": "ID167",
"message": "New entry",
"pid": "28968",
"syslog_priority": "14",
"syslog_version": "1",
"timestamp": "2025-06-23T10:24:44.849103Z"
}
}
Options
Select a telemetry type
You can specify, log, metric, trace or all. It is specified using the interface, which generates a YAML list item for you under the data_types parameter. This defines the data item types against which the processor must operate. If data_types is not specified, the default value is all. It is optional.
It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
data_types:
- log
condition
The condition parameter contains a conditional phrase of an OTTL statement. It restricts operation of the processor to only data items where the condition is met. Those data items that do not match the condition are passed without processing. You configure it in the interface and an OTTL condition is generated. It is optional.
Important: All conditions must be written on a single line in YAML. Multi-line conditions are not supported.
Comparison Operators
| Operator | Name | Description | Example |
|---|---|---|---|
== | Equal to | Returns true if both values are exactly the same | attributes["status"] == "OK" |
!= | Not equal to | Returns true if the values are not the same | attributes["level"] != "debug" |
> | Greater than | Returns true if the left value is greater than the right | attributes["duration_ms"] > 1000 |
>= | Greater than or equal | Returns true if the left value is greater than or equal to the right | attributes["score"] >= 90 |
< | Less than | Returns true if the left value is less than the right | attributes["load"] < 0.75 |
<= | Less than or equal | Returns true if the left value is less than or equal to the right | attributes["retries"] <= 3 |
matches | Regex match | Returns true if the string matches a regular expression (generates IsMatch function) | IsMatch(attributes["name"], ".*\\.log$") |
Logical Operators
Important: Use lowercase and, or, not - uppercase operators will cause errors!
| Operator | Description | Example |
|---|---|---|
and | Both conditions must be true | attributes["level"] == "ERROR" and attributes["status"] >= 500 |
or | At least one condition must be true | attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT" |
not | Negates the condition | not IsMatch(attributes["path"], "^/health") |
Functions
| Function | Description | Example |
|---|---|---|
IsMatch | Returns true if string matches the regex pattern | IsMatch(attributes["message"], "ERROR\|FATAL") |
Field Existence Checks
| Check | Description | Example |
|---|---|---|
!= nil | Field exists (not null) | attributes["user_id"] != nil |
== nil | Field doesn’t exist | attributes["optional_field"] == nil |
!= "" | Field is not empty string | attributes["message"] != "" |
Common Examples
- name: _multiprocessor
type: sequence
processors:
- type: <processor type>
# Simple equality check
condition: attributes["request"]["path"] == "/json/view"
- type: <processor type>
# Multiple values with OR
condition: attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT"
- type: <processor type>
# Excluding multiple values (NOT equal to multiple values)
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
- type: <processor type>
# Complex condition with AND/OR/NOT
condition: (attributes["level"] == "ERROR" or attributes["level"] == "FATAL") and attributes["env"] != "test"
- type: <processor type>
# Field existence and value check
condition: attributes["user_id"] != nil and attributes["user_id"] != ""
- type: <processor type>
# Regex matching on attributes
condition: IsMatch(attributes["path"], "^/api/") and not IsMatch(attributes["path"], "^/api/health")
- type: <processor type>
# Regex matching on body (case-insensitive)
condition: IsMatch(body, "(?i)error")
Common Mistakes to Avoid
# WRONG - Cannot use OR/AND with values directly
condition: attributes["log_type"] != "TRAFFIC" OR "THREAT"
# CORRECT - Must repeat the full comparison
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
# WRONG - Uppercase operators
condition: attributes["status"] == "error" AND attributes["level"] == "critical"
# CORRECT - Lowercase operators
condition: attributes["status"] == "error" and attributes["level"] == "critical"
# WRONG - Multi-line conditions
condition: |
attributes["level"] == "ERROR" and
attributes["status"] >= 500
# CORRECT - Single line (even if long)
condition: attributes["level"] == "ERROR" and attributes["status"] >= 500
OTTL Statement
Parse from
This option specifies the field containing the text that needs to be parsed. It is specified using bracket notation and is optional. If left empty it defaults to body.
Assign to
Specify the field where you want the parsed object to be saved.
Grok Pattern
This option defines the log pattern that should be used to parse attributes. A Pattern or a Custom Pattern is required. Use the Knowledge Library to select a pattern, specify your own a custom pattern, or you use an AI assistant to generate a Grok pattern.
Error mode
Minimum Agent Version: v2.11.0
Controls how the processor handles parsing errors. Available under Advanced Settings in the UI.
| Mode | Description |
|---|---|
silent | (Default) Suppresses error logs for parsing failures. Use this when parsing errors are expected and don’t require investigation. |
strict | Logs errors when parsing fails. Use this when you need visibility into parsing failures for debugging or validation. |
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
error_mode: silent
Final
Determines whether successfully processed data items should continue through the remaining processors in the same processor stack. If final is set to true, data items output by this processor are not passed to subsequent processors within the node—they are instead emitted to downstream nodes in the pipeline (e.g., a destination). Failed items are always passed to the next processor, regardless of this setting.
The UI provides a slider to configure this setting. The default is false. It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
final: true
Keep original telemetry item
Controls whether the original, unmodified telemetry item is preserved after processing. If keep_item is set to true, the processor emits both:
- The original telemetry item (e.g., a log), and
- Any new item generated by the processor (e.g., a metric extracted from the log)
Both items are passed to the next processor in the stack unless final is also set.
Interaction with final
If final: true is enabled, any successfully processed data items, whether original, newly created, or both, exit the processor stack or node immediately. No subsequent processors within the same node are evaluated, although downstream processing elsewhere in the pipeline continues. This means:
- If
keep_item: trueandfinal: true, both the original and processed items bypass the remaining processors in the current node and are forwarded to downstream nodes (such as destinations). - If
keep_item: falseandfinal: true, only the processed item continues beyond this processor, skipping subsequent processors in the stack, and the original item is discarded.
Note: If the data item fails to be processed, final has no effect, the item continues through the remaining processors in the node regardless of the keep_item setting.
The app provides a slider to configure keep_item. The default is false.
- name: ed_gateway_output_a3fa_multiprocessor
type: sequence
processors:
- type: <processor_type>
keep_item: true
final: true
Configuration Wizard
Use this interactive wizard to generate a starter configuration:
What type of logs are you parsing?
Select a log format to get a pre-built grok pattern, or use a custom pattern.
See Also
- For an overview and to understand processor sequence flow, see Processors Overview
- To learn how to configure a processor, see Configure a Processor.
- For optimization strategies, see Best Practices for Edge Delta Processors.
- If you’re new to pipelines, start with the Pipeline Quickstart Overview or learn how to Configure a Pipeline.
- Looking to understand how processors interact with sources and destinations? Visit the Pipeline Overview.