Rehydrations
Query and replay historical logs from archive storage to observability destinations for incident investigation, compliance audits, and data backfilling.
4 minute read
Edge Delta Rehydrations enable you to query and replay historical logs from your archive storage (S3, GCS, or MinIO) and send them to your observability destinations (Splunk, Elasticsearch, Dynatrace, or Google Cloud Logging).
Rehydration is a separate distributed service that runs in your Kubernetes cluster alongside your Edge Delta agents. It requires its own deployment and infrastructure to handle the compute-intensive task of reading, transforming, and streaming archived data.
For organizations with multiple archive sources and destinations, you can configure mapping rules to auto-populate source and destination fields based on your query.
Use Cases
Incident investigation: When investigating production issues, you often need access to logs from weeks or months ago. Rehydrations allow you to retrieve historical data that has been moved to archive storage, enabling thorough root cause analysis without maintaining expensive hot storage for all historical data.
Data backfilling: When adding a new observability destination or migrating between platforms, you can use rehydrations to populate the new system with historical data. This ensures continuity of your observability data across platform changes.
Compliance and audits: Regulatory requirements often mandate log retention for extended periods. Rehydrations enable you to query archived logs across long time ranges to satisfy audit requests and compliance investigations without keeping all data in active storage.
Cost-effective retention: By archiving logs to inexpensive object storage like S3 or GCS and rehydrating on demand, you can maintain access to historical data while significantly reducing storage costs compared to keeping everything in hot storage.
Architecture
The rehydration system uses a distributed architecture designed for scalability and fault tolerance. Unlike the Edge Delta agent which runs as a DaemonSet collecting live telemetry, rehydration runs as a separate set of components dedicated to processing archived data.
Components
The architecture consists of five main components:
- Rehydration Manager: A single-pod Kubernetes deployment that orchestrates rehydration jobs. It polls for new requests, lists files in source storage, distributes work, and aggregates results.
- NATS JetStream: A message queue that distributes tasks to workers and collects results. Tasks are published to a task topic, and workers report back via a result topic.
- Workers: Stateless pods that process rehydration tasks. Each worker reads data from archive storage, applies filters and transformations, and pushes the results to the destination. Workers scale from 0 to n based on workload.
- KEDA: An autoscaler that monitors the JetStream queue depth and scales workers from zero to the configured maximum based on workload.
- ClickHouse: A query engine used for reading from object storage and processing archived data.
Processing Flow
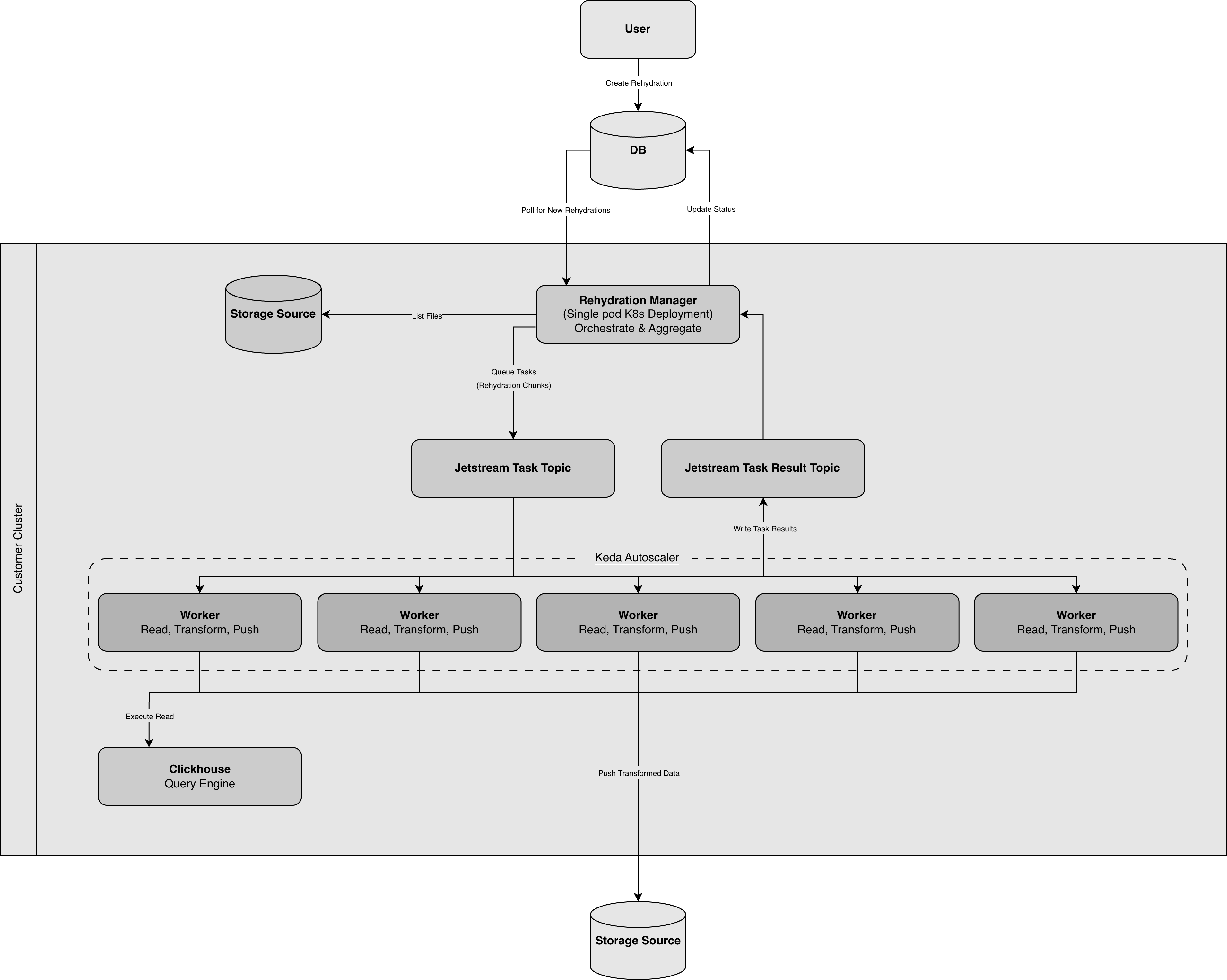
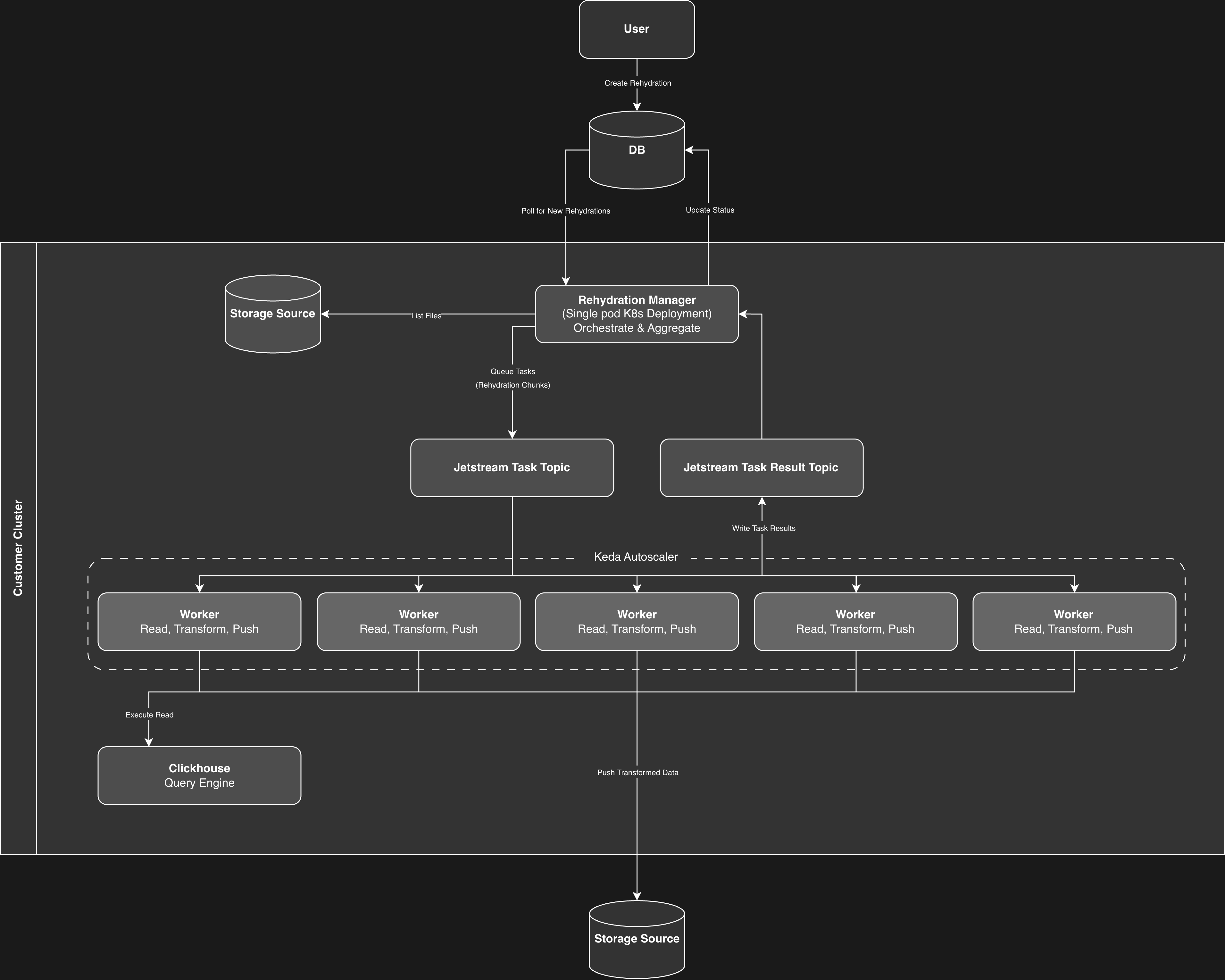
Flow Details
- Request Creation: A user creates a rehydration request in the Edge Delta UI specifying time range, source, and destination. The request is stored with a
Createdstatus. - Manager Polling: The Rehydration Manager continuously polls for new requests. When it finds one, it claims the request and updates the status to
Invoked. - File Discovery: The Manager lists all relevant files from the source storage (S3, GCS, or MinIO) that match the specified time range.
- Task Distribution: Files are chunked into manageable tasks (based on size, typically 50MB chunks) and published to the JetStream task topic. The status updates to
In Progress. - Worker Autoscaling: KEDA monitors the JetStream queue depth. When tasks are queued, it scales workers from zero up to the configured maximum. When the queue empties, workers scale back to zero.
- Task Processing: Each worker pulls a task from the queue, reads the assigned files from archive storage, applies filtering logic, transforms data to the destination format, streams data to the destination, and reports results back via the result topic.
- Result Aggregation: The Manager listens for task results and aggregates them. If a task fails or is cancelled, the rehydration can terminate early.
- Completion: Once all tasks complete, the Manager updates the final status (
CompletedorFailed) along with performance metrics.
Scalability
The architecture scales efficiently through several mechanisms:
- Zero-to-many workers: Workers scale to zero when idle, minimizing costs, and scale up rapidly when work is queued.
- Parallel processing: Multiple workers process tasks concurrently, with each worker handling its own subset of files.
- Streaming design: Data streams through the pipeline without blocking, maintaining high throughput.
- Decoupled components: The Manager and Workers operate independently, enabling robust task orchestration and fault handling.
Archive Sources
Rehydrations support the following archive storage types:
- AWS S3: Using IAM roles or access keys
- Google Cloud Storage: Using service accounts or workload identity
- MinIO: S3-compatible storage
Supported Destinations
Rehydrated logs can be sent to:
- Splunk: Via HEC endpoint
- Elasticsearch: Direct API ingestion
- Dynatrace: Log ingestion API
- Google Cloud Logging: Native integration