Edge Delta Splunk Load Balanced Destination
12 minute read
Overview
The Splunk Load Balanced destination automatically discovers available indexers from a Splunk cluster manager and distributes data across them. This provides automatic load balancing and improved reliability compared to sending data to a single endpoint.
The node periodically queries the cluster manager to retrieve the current list of active indexers, enabling dynamic adaptation to cluster topology changes without manual configuration updates.
- incoming_data_types: cluster_pattern_and_sample, health, heartbeat, log, metric, custom, splunk_payload, signal
Note: This node is currently in beta and is available for Enterprise tier accounts.
This node requires Edge Delta agent version v2.9.0 or higher.
Example Configuration
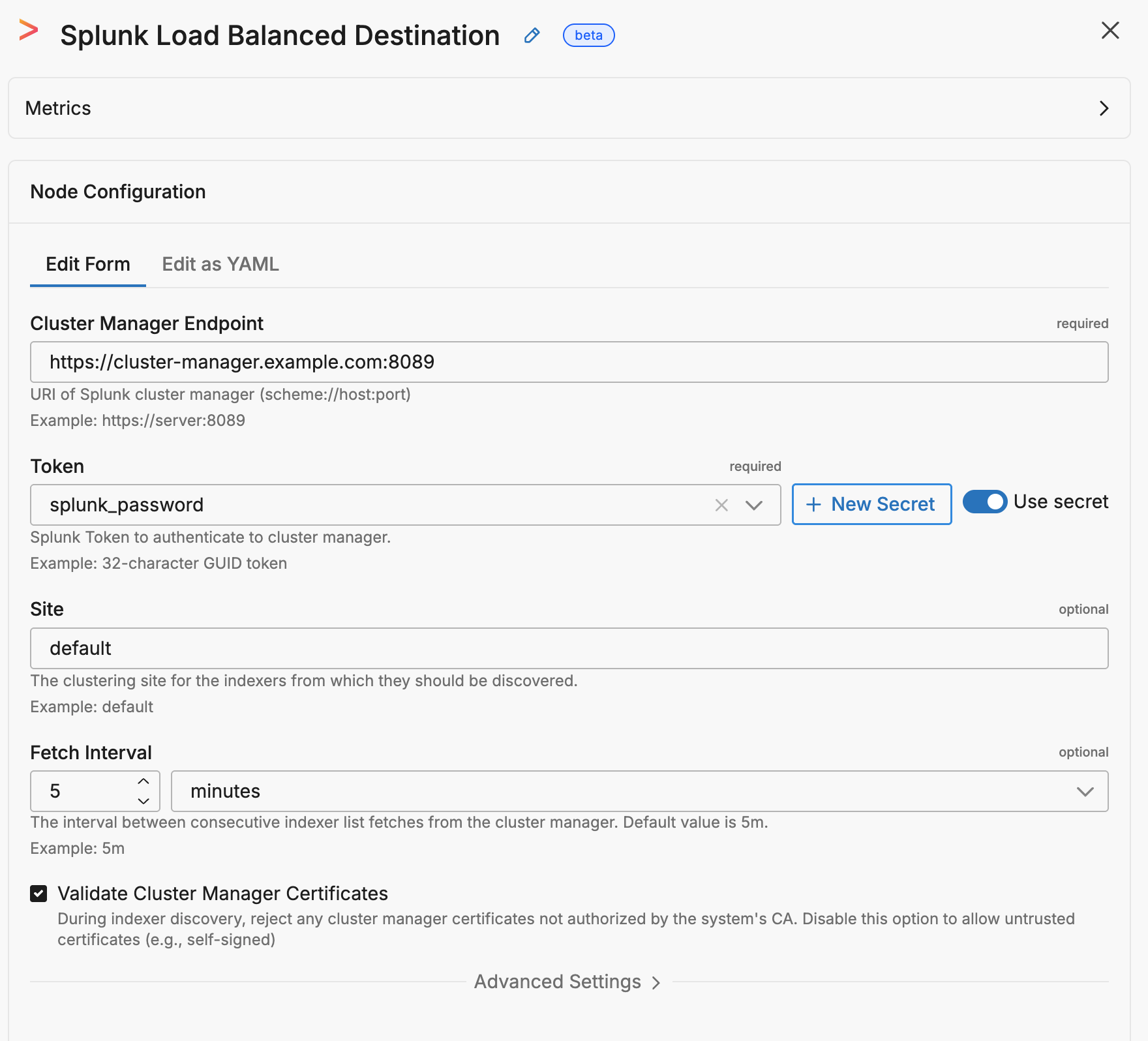
This configuration connects to a Splunk cluster manager and automatically discovers indexers to load balance data across.
nodes:
- name: splunk_lb
type: splunk_lb_output
endpoint: "https://cluster-manager.example.com:8089"
token: '{{ SECRET splunk_password }}'
site: default
fetch_interval: 5m0s
validate_cluster_manager_certs: true
See Secrets for information on securely storing credentials.
Required Parameters
name
A descriptive name for the node. This is the name that will appear in pipeline builder and you can reference this node in the YAML using the name. It must be unique across all nodes. It is a YAML list element so it begins with a - and a space followed by the string. It is a required parameter for all nodes.
nodes:
- name: <node name>
type: <node type>
type: splunk_lb_output
The type parameter specifies the type of node being configured. It is specified as a string from a closed list of node types. It is a required parameter.
nodes:
- name: <node name>
type: <node type>
endpoint
The Splunk cluster manager endpoint URI in the format scheme://host:port. This is the management port of your cluster manager, typically port 8089.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: "https://cluster-manager.example.com:8089"
token: <token>
token
Splunk token to authenticate with the cluster manager.
This field supports secret references for secure credential management. Instead of hardcoding sensitive values, you can reference a secret configured in your pipeline.
To use a secret in the GUI:
- Create a secret in your pipeline’s Settings > Secrets section (see Secrets)
- In this field, select the secret name from the dropdown list that appears
To use a secret in YAML:
Reference it using the syntax: '{{ SECRET secret-name }}'
Example:
field_name: '{{ SECRET my-credential }}'
Note: The secret reference must be enclosed in single quotes when using YAML. Secret values are encrypted at rest and resolved at runtime, ensuring no plaintext credentials appear in logs or API responses.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: '{{ SECRET splunk_token }}'
Optional Parameters
disabled
The disabled parameter disables the node in the pipeline. When set to true, the agent ignores the node at startup. You can toggle nodes on or off in the pipeline builder. It is specified as a boolean, defaults to false, and is optional.
nodes:
- name: <node name>
type: <node type>
disabled: true
site
The clustering site from which indexers should be discovered. Use this to target indexers in a specific site within a multi-site cluster. Default is default.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
site: site1
fetch_interval
The interval between consecutive indexer list fetches from the cluster manager. The node periodically queries the cluster manager to discover new indexers or detect removed ones. Default is 5m.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
fetch_interval: 10m
validate_cluster_manager_certs
When enabled, the node validates the cluster manager’s TLS certificate against the system’s certificate authorities during indexer discovery. Disable this option to allow self-signed or untrusted certificates. Default is false.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
validate_cluster_manager_certs: true
index_expression
OTTL expression to dynamically extract and apply the Splunk index from data attributes instead of using a static index. This allows routing different data to different indexes based on data content.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
index_expression: attributes["splunk_index"]
keep_overridden_index
When set to true, the attribute used for index override (specified in index_expression) is retained in the data. When false, the attribute is removed after the index is extracted. Default is false.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
index_expression: attributes["splunk_index"]
keep_overridden_index: true
parallel_worker_count
Number of parallel workers for sending data to indexers. Increase this value to improve throughput for high-volume data streams. Default is 2.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
parallel_worker_count: 4
tls
TLS configuration for secure connections to Splunk indexers.
| Field | Description | Default |
|---|---|---|
enabled | Enable TLS for indexer connections | false |
ignore_certificate_check | Disable certificate verification (not recommended for production) | false |
ca_file | Path to CA certificate file | - |
crt_file | Path to client certificate file | - |
key_file | Path to client private key file | - |
min_version | Minimum TLS version (TLSv1_2, TLSv1_3) | TLSv1_2 |
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
tls:
enabled: true
ca_file: /etc/ssl/certs/splunk-ca.crt
enable_indexer_discovery
The enable_indexer_discovery parameter enables automatic indexer discovery from the cluster manager. When enabled, the node queries the cluster manager to retrieve the list of available indexers. It is specified as a Boolean and is optional.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
enable_indexer_discovery: true
weighted_destinations
The weighted_destinations parameter specifies indexer endpoints with custom weights for load distribution. Each entry includes an endpoint and a weight value that determines the proportion of traffic routed to that indexer. It is specified as a list of weighted destination objects and is optional.
nodes:
- name: <node name>
type: splunk_lb_output
endpoint: <endpoint>
token: <token>
weighted_destinations:
- endpoint: "https://indexer1.example.com:9997"
weight: 3
- endpoint: "https://indexer2.example.com:9997"
weight: 1
persistent_queue
The persistent_queue configuration enables disk-based buffering to prevent data loss during destination failures or slowdowns. When enabled, the agent stores data on disk and automatically retries delivery when the destination recovers.
Complete example:
persistent_queue:
path: /var/lib/edgedelta/outputbuffer
mode: error
max_byte_size: 1GB
drain_rate_limit: 1000
How it works:
- Normal operation: Data flows directly to the destination (for
errorandbackpressuremodes) or through the disk buffer (foralwaysmode) - Destination issue detected: Based on the configured
mode, data is written to disk at the configuredpath - Recovery: When the destination recovers, buffered data drains at the configured
drain_rate_limitwhile new data continues flowing - Completion: Buffer clears and normal operation resumes
Key benefits:
- Data durability: Logs preserved during destination outages and slowdowns
- Agent protection: Slow backends don’t cascade failures into the agent cluster
- Automatic recovery: No manual intervention required
- Configurable behavior: Choose when and how buffering occurs based on your needs
Learn more: Buffer Configuration - Conceptual overview, sizing guidance, and troubleshooting
path
The path parameter specifies the directory where buffered data is stored on disk. This parameter is required when configuring a persistent queue.
Example:
persistent_queue:
path: /var/lib/edgedelta/outputbuffer
Requirements:
- Required field - persistent queue will not function without a valid path
- The directory must have sufficient disk space for the configured
max_byte_size - The agent process must have read/write permissions to this location
- The path should be on a persistent volume (not tmpfs or memory-backed filesystem)
Best practices:
- Use dedicated storage for buffer data separate from logs
- Monitor disk usage to prevent buffer from filling available space
- Ensure the path persists across agent restarts to maintain buffered data
max_byte_size
The max_byte_size parameter defines the maximum disk space the persistent buffer is allowed to use. Once this limit is reached, any new incoming items are dropped, ensuring the buffer never grows beyond the configured maximum.
Note: This limit is total storage for the persistent queue, not per-worker. If you configure
max_byte_size: 1GBand the destination has 15 workers, the buffer uses 1GB total, not 15GB.
Example:
persistent_queue:
path: /var/lib/edgedelta/outputbuffer
max_byte_size: 1GB
Sizing guidance:
- Small deployments (1-10 logs/sec): 100MB - 500MB
- Medium deployments (10-100 logs/sec): 500MB - 2GB
- Large deployments (100+ logs/sec): 2GB - 10GB
Calculation example:
Average log size: 1KB
Expected outage duration: 1 hour
Log rate: 100 logs/sec
Buffer size = 1KB × 100 logs/sec × 3600 sec = 360MB
Recommended: 500MB - 1GB (with safety margin)
Important: Set this value based on your disk space availability and expected outage duration. The buffer will accumulate data during destination failures and drain when the destination recovers.
mode
The mode parameter determines when data is buffered to disk. Three modes are available:
error(default) - Buffers data only when the destination returns errors (connection failures, HTTP 5xx errors, timeouts). During healthy operation, data flows directly to the destination without buffering.backpressure- Buffers data when the in-memory queue reaches 80% capacity OR when destination errors occur. This mode helps handle slow destinations that respond successfully but take longer than usual to process requests.always- Uses write-ahead-log behavior where all data is written to disk before being sent to the destination. This provides maximum durability but adds disk I/O overhead to every operation.
Example:
persistent_queue:
path: /var/lib/edgedelta/outputbuffer
mode: error
max_byte_size: 1GB
Mode comparison:
| Mode | Protects Against | Trade-off | Recommended For |
|---|---|---|---|
error | Destination outages and failures | No protection during slow responses | Reliable destinations with consistent response times |
backpressure | Outages + slow/degraded destinations | Slightly more disk writes during slowdowns | Most production deployments |
always | All scenarios including agent crashes | Disk I/O on every item reduces throughput | Maximum durability requirements |
Why choose error mode:
The error mode provides the minimal protection layer needed to prevent data loss when destinations temporarily fail. Without any persistent queue, a destination outage means data is lost. With error mode enabled, data is preserved on disk during failures and delivered automatically when the destination recovers.
Why choose backpressure mode:
The backpressure mode provides everything error mode offers, plus protection against slow destinations. When a destination is slow but not completely down:
- Without
backpressure: Data delivery becomes unreliable, and the backend’s slowness propagates to the agent—the agent can get stuck waiting before sending subsequent payloads - With
backpressure: The agent spills data to disk and continues processing, isolating itself from the slow backend
This prevents a slow destination from cascading failures into your agent cluster. For most production environments, backpressure provides the best balance of protection and performance.
Why choose always mode:
The always mode is designed for customers with extremely strict durability requirements. It forces the agent to write every item to disk before attempting delivery, then reads from disk for transmission. This guarantees that data survives even sudden agent crashes or restarts.
Important: This mode introduces a measurable performance cost. Each agent performs additional disk I/O on every item, which reduces overall throughput. Most deployments do not require this level of durability—this feature addresses specialized needs that apply to a small minority of customers.
Only enable always mode if you have a specific, well-understood requirement where the durability guarantee outweighs the throughput reduction.
strict_ordering
The strict_ordering parameter controls how items are consumed from the persistent buffer.
When strict_ordering: true, the agent runs in strict ordering mode with a single processing thread. This mode always prioritizes draining buffered items first—new incoming data waits until all buffered items are processed in exact chronological order. When strict_ordering: false (default), multiple workers process data in parallel, and new data flows directly to the destination while buffered data drains in the background.
Example:
persistent_queue:
path: /var/lib/edgedelta/outputbuffer
mode: always
strict_ordering: true
parallel_workers: 1
Default value: false
Important: Strict ordering is a specialized feature needed by a very small minority of deployments. Most users should keep the default value of false. Only enable strict ordering if you have a specific, well-understood requirement for exact event sequencing.
Required setting: When strict_ordering: true, you must set parallel_workers: 1. Pipeline validation will fail if parallel_workers is greater than 1 because parallel processing inherently breaks ordering guarantees.
Behavior:
| Value | Processing Model | Buffer Priority | Recovery Latency |
|---|---|---|---|
false (default) | Parallel workers | Buffered data drains in background | Lower - current state visible immediately |
true | Single-threaded | Buffered items always drain first | Higher - queue must drain before new data |
Why the default is false:
In most observability use cases, data freshness is more valuable than strict ordering. When a destination recovers from an outage, operators typically want to see current system state on dashboards immediately, while historical data backfills in the background. The default behavior prioritizes this real-time visibility.
When to enable strict ordering:
Strict ordering is primarily needed by security-focused customers who build systems where events must arrive in the exact delivery order. These customers typically run stateful security streaming engines that depend on precise temporal sequencing.
Specific use cases:
- Stateful security streaming engines - Security systems that maintain state across events and detect patterns based on exact event order
- Audit and compliance logs - Regulatory requirements that mandate audit trails preserve exact temporal sequence
- State reconstruction - Systems that replay events to rebuild state require chronological order
When to keep default (false):
The vast majority of deployments should keep the default:
- Real-time monitoring dashboards - Current state visibility is more important than historical order
- High-volume log ingestion - Faster drain times reduce recovery period
- Stateless analytics - When each log is analyzed independently without temporal correlation
drain_rate_limit
The drain_rate_limit parameter controls the maximum items per second when draining the persistent buffer after a destination recovers from a failure.
Example:
persistent_queue:
path: /var/lib/edgedelta/outputbuffer
drain_rate_limit: 1000
Default value: 0 (no limit - drain as fast as the destination accepts)
Why rate limiting matters:
When a destination recovers from an outage, it may still be fragile. Immediately flooding it with hours of backlogged data can trigger another failure. The drain rate limit allows gradual, controlled recovery that protects destination stability.
Choosing the right rate:
| Scenario | Recommended Rate | Reasoning |
|---|---|---|
| Stable, well-provisioned destination | 0 (unlimited) | Minimize recovery time when destination can handle full load |
| Shared or multi-tenant destination | 20-50% of capacity | Leave headroom for live traffic and other tenants |
| Recently recovered destination | 10-25% of capacity | Gentle ramp-up to prevent re-triggering failure |
| Rate-limited destination (e.g., SaaS) | Below API rate limit | Avoid throttling or quota exhaustion |
Impact on recovery time:
Buffer size: 1GB
Average log size: 1KB
Total items: ~1,000,000 logs
At unlimited (0): Depends on destination capacity
At 5000: ~3.5 minutes to drain
At 1000: ~17 minutes to drain
At 100: ~2.8 hours to drain
How It Works
- Discovery: The node connects to the Splunk cluster manager and queries for available indexers in the specified site.
- Load Balancing: Incoming data is distributed across discovered indexers using a load balancing algorithm.
- Refresh: The indexer list is refreshed at the configured
fetch_intervalto detect topology changes. - Failover: If an indexer becomes unavailable, data is automatically routed to other healthy indexers.
Use Cases
High-Availability Splunk Ingestion
Automatically distribute logs across all available indexers in your Splunk cluster for improved throughput and resilience.
nodes:
- name: splunk_ha
type: splunk_lb_output
endpoint: "https://cluster-manager:8089"
token: '{{ SECRET splunk_token }}'
fetch_interval: 5m
parallel_worker_count: 4
persistent_queue:
path: /var/lib/edgedelta/splunk-buffer
max_byte_size: 2GB
mode: error
Multi-Site Cluster Targeting
Send data to indexers in a specific site within a multi-site Splunk deployment.
nodes:
- name: splunk_site1
type: splunk_lb_output
endpoint: "https://cluster-manager:8089"
token: '{{ SECRET splunk_token }}'
site: site1
validate_cluster_manager_certs: true
Dynamic Index Routing
Route data to different Splunk indexes based on data attributes.
nodes:
- name: splunk_dynamic
type: splunk_lb_output
endpoint: "https://cluster-manager:8089"
token: '{{ SECRET splunk_token }}'
index_expression: attributes["target_index"]
keep_overridden_index: false