Edge Delta Anomaly Detection
3 minute read
Edge Delta automatically detects anomalies in observability data, in individual agents as well as in aggregate on the backend. Site Reliability Engineers (SREs) and developer teams can receive alerts about anomalous behavior and see views designed to help with root cause analysis. This helps reduce the time needed to detect and resolve incidents.
Anomalies in Log Patterns
Once log patterns are streamed to the Edge Delta backend, monitors can be configured to detect anomalous behavior and trigger alerts to one or more notification channels.
OnCall AI
The Logs - Anomalies page shows results of your monitors. Monitors analyze a pattern’s behavior to detect anomalies. Each anomaly is interpreted using OnCall AI which summarizes it and provides recommendations on how to remediate it.
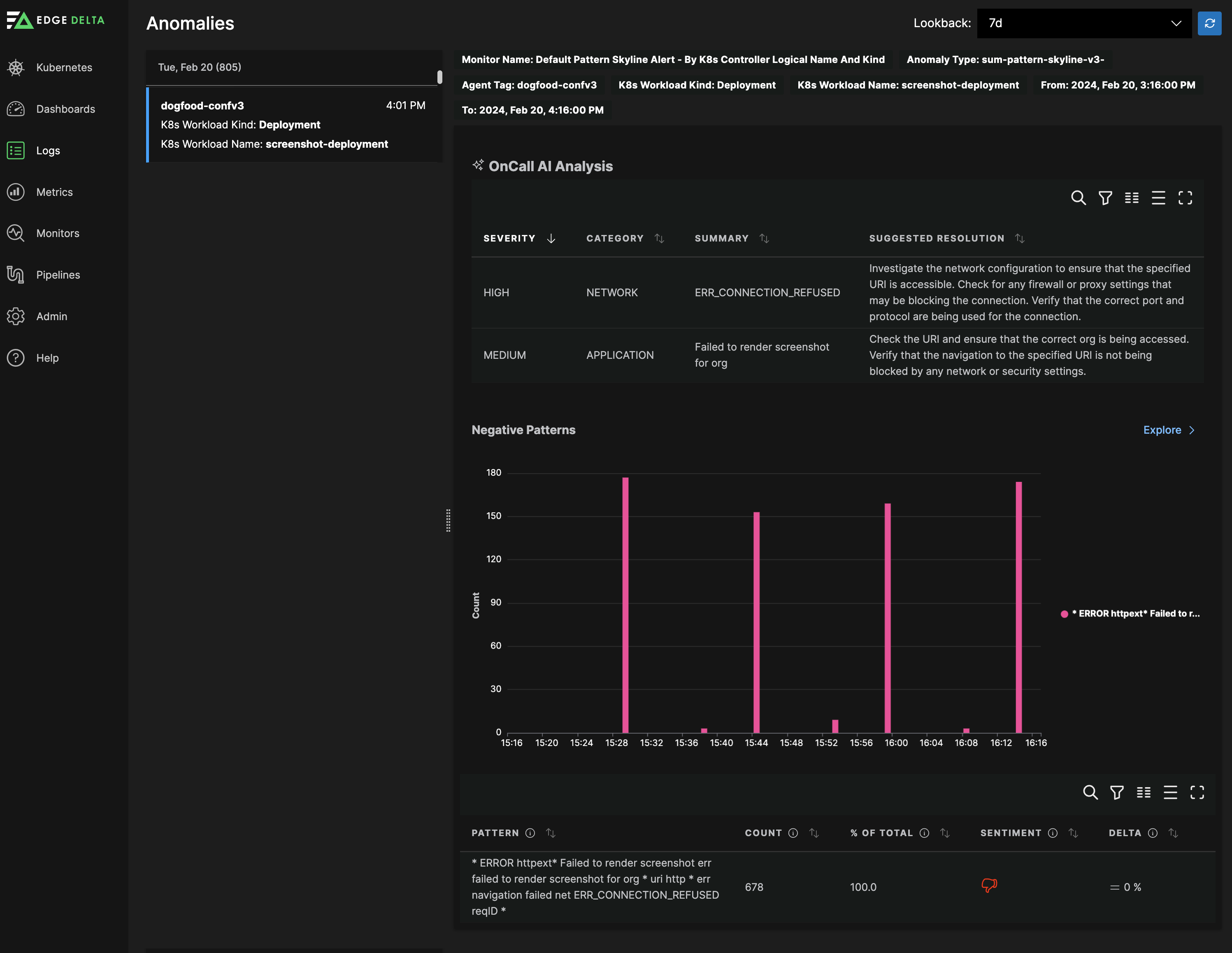
OnCall AI:
- Analyzes the contents of the logs contributing to the anomaly.
- Communicates the severity of the issue and what it’s impacting.
- Summarizes the negative behavior in conversational text.
- Provides a recommendation on how to resolve the issue.
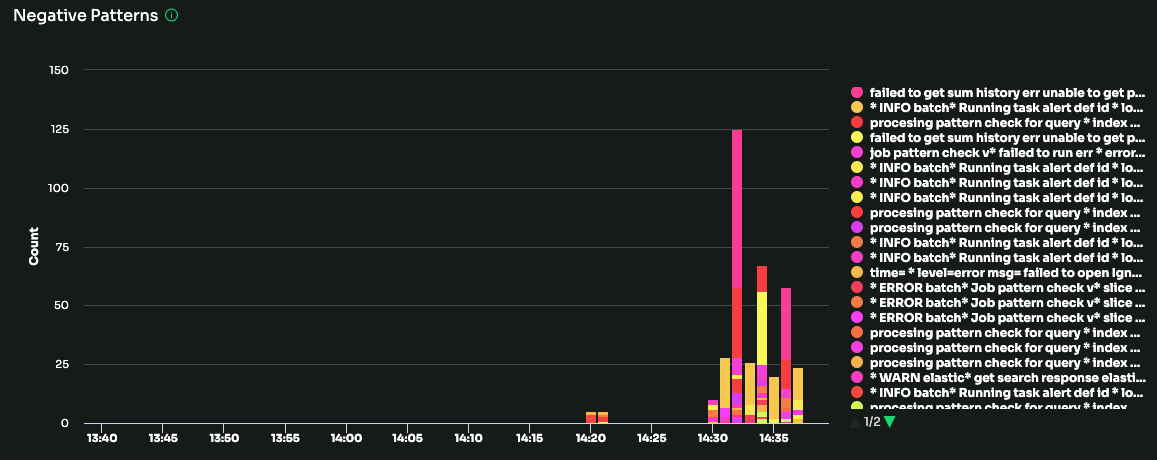
Skyline Pattern Monitor
The Skyline Pattern monitor uses a proprietary ‘skyline’ algorithm to detect unusual spikes in logs with negative sentiment. Log patterns for a particular source (e.g. a Kubernetes namespace or controller) are analyzed in aggregate, and an alert will be triggered if there is an unusual spike in either the total number of log messages with negative sentiment, or the number of unique negative patterns detected.
The algorithm is tuned to reduce false positives by accounting for repeated patterns (e.g. logs that result from a daily/weekly/monthly batch job) as well as normal fluctuations in log volume (e.g. increased traffic to a website during daytime hours).
Anomalies in Metrics
After performing logs to metrics conversion, Edge Delta is able to detect anomalies in the data collected by individual agents as well as in data aggregated from multiple agents.
Agent Processor Alerts
The Edge Delta agent can be configured to track the value of log metrics over time, detect anomalous values, and alert you if it finds any.
For instance, you may want to alerted if there is unusually high frequency of log messages containing ERROR or EXCEPTION. To determine if the frequency is unusually high, the agent calculates an anomaly score between 0 to 100 using a proprietary algorithm, and if the metric value exceeds a defined threshold during a given interval, the value will be considered anomalous.
processors:
regexes:
- name: error-monitoring
trigger_thresholds:
anomaly_probability_percentage: 95
retention: 12h0m0s
pattern: (?i)error
- name: exception-monitoring
trigger_thresholds:
anomaly_probability_percentage: 95
retention: 12h0m0s
pattern: (?i)exception
Depending on configuration, an alert may be sent (typically a Slack message or an email), and an anomaly capture may occur, resulting in raw logs around the time of the anomaly being sent to the Edge Delta backend and/or a 3rd party streaming destination.
Metrics Alert Monitors
Since many production services run across multiple hosts, it is often useful to collect metric values in aggregate from all hosts, analyze them, and trigger alerts if a threshold is exceeded.
A metrics alert monitor can be configured to trigger when the aggregated metric value or anomaly score from many agent instances exceeds a defined threshold. Click Create Alert on the Metrics view in the web app to define a metric alert.
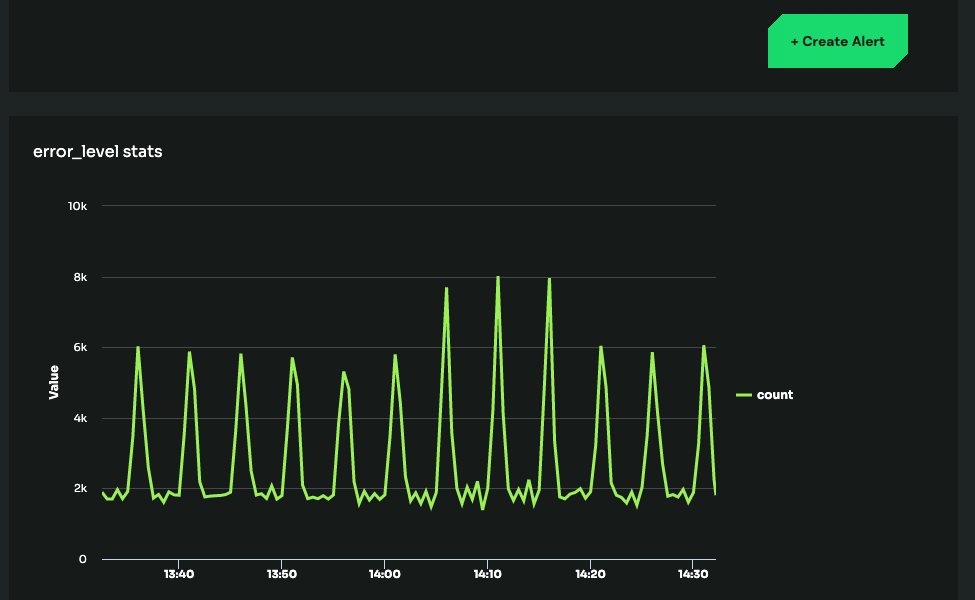
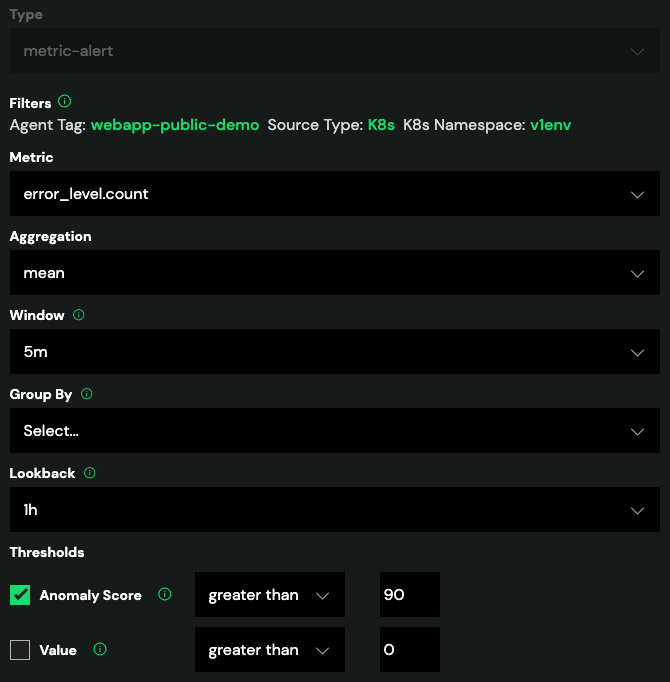
When the threshold defined in a metrics alert monitor is exceeded, a notification is sent (via email, Slack, Pager Duty, etc.) with a link to an Investigation view, similar to that for a processor-detected metric anomaly.