Edge Delta Route Processor
6 minute read
Overview
The Route (OTTL) node enables conditional routing of log data through user-defined paths based on OTTL expressions. Each path acts as a logical branch that receives items matching a specific condition.
Use the configuration wizard below to generate a starter YAML configuration.
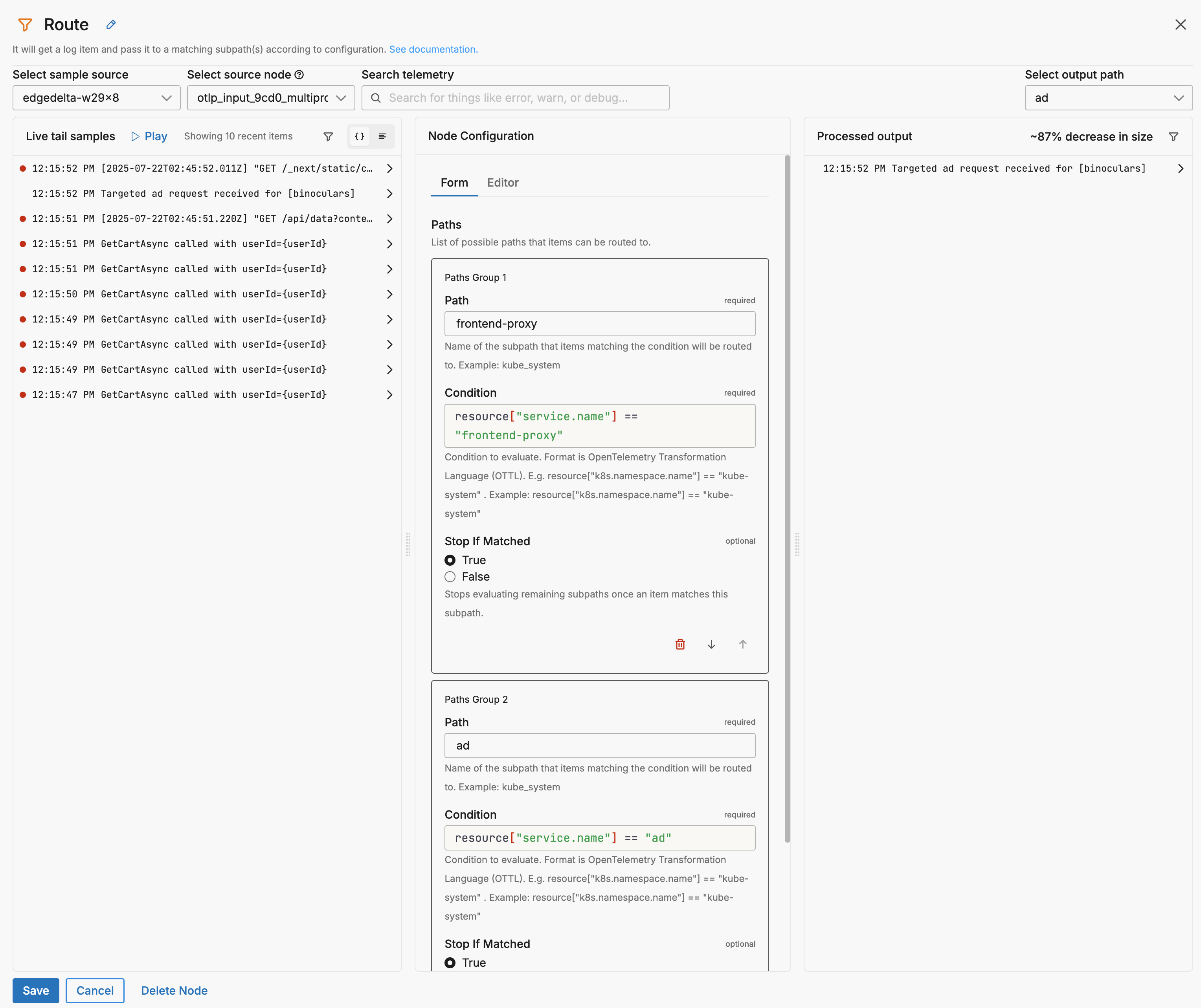
You can view the output of each path in Live Capture:
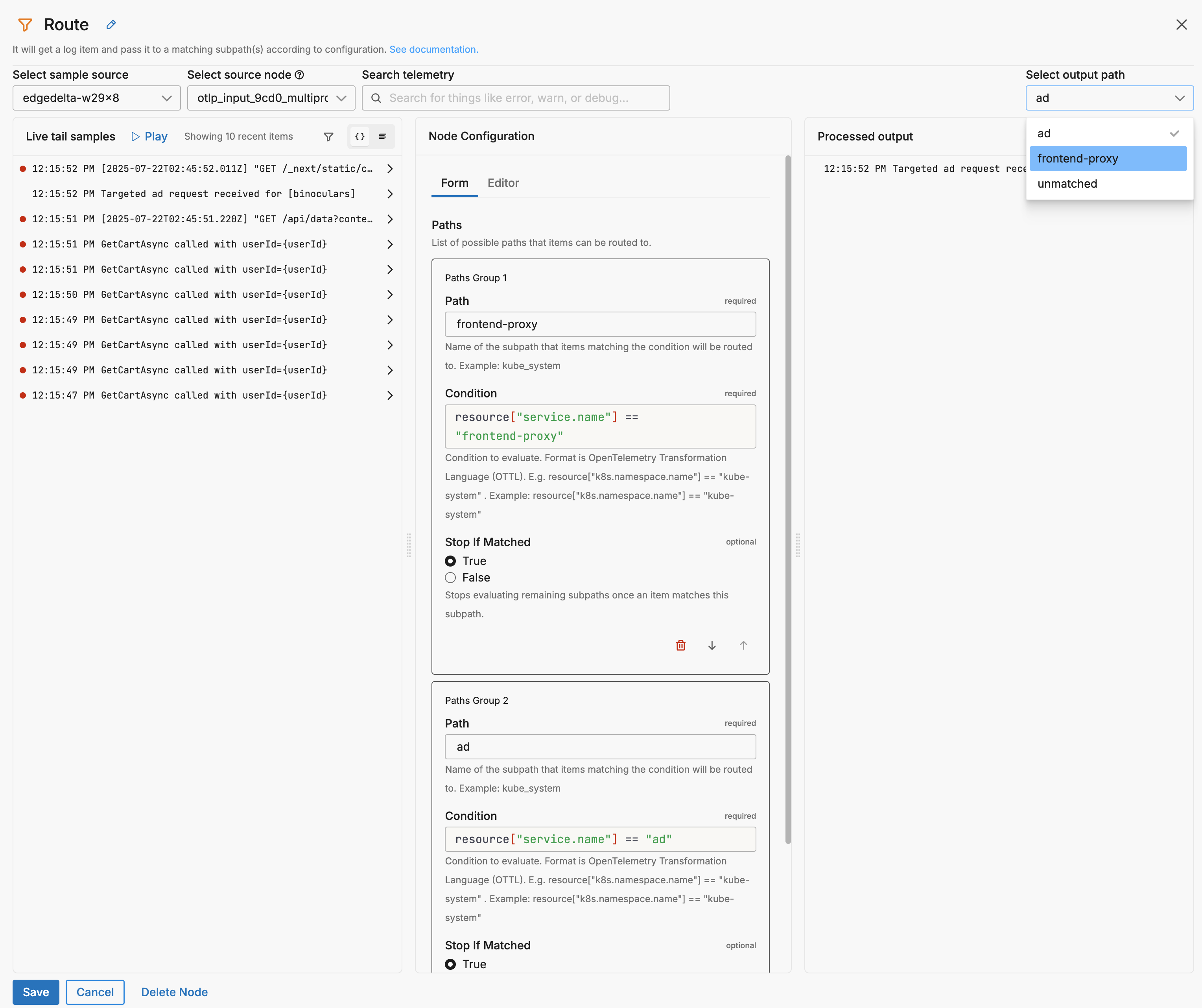
Note: This processor replaces the legacy route node.
This node requires Edge Delta agent version v2.3.0 or higher.
Example Configuration
You can define multiple paths, each with a condition and optional Stop If Matched control. Items that meet a condition will be routed to the corresponding subpath for downstream processing.
nodes:
- name: route_ottl_a72f
type: route_ottl
paths:
- path: Frontend-Proxy
condition: resource["service.name"] == "frontend-proxy"
exit_if_matched: true
- path: Ad
condition: resource["service.name"] == "ad"
exit_if_matched: true
Options
Path
Define the name for the path that data items will be routed to if they match the path’s condition. Each path must include a condition.
paths:
- path: type_1_items
condition: attributes["value"] == "1"
A default unmatched path in configured for items that don’t match any path.
condition
The condition parameter contains a conditional phrase of an OTTL statement. It defines the matching criteria for data items to be routed on the path. You configure it in the interface and an OTTL condition is generated. It is required.
Important: All conditions must be written on a single line in YAML. Multi-line conditions are not supported.
Comparison Operators
| Operator | Name | Description | Example |
|---|---|---|---|
== | Equal to | Returns true if both values are exactly the same | attributes["status"] == "OK" |
!= | Not equal to | Returns true if the values are not the same | attributes["level"] != "debug" |
> | Greater than | Returns true if the left value is greater than the right | attributes["duration_ms"] > 1000 |
>= | Greater than or equal | Returns true if the left value is greater than or equal to the right | attributes["score"] >= 90 |
< | Less than | Returns true if the left value is less than the right | attributes["load"] < 0.75 |
<= | Less than or equal | Returns true if the left value is less than or equal to the right | attributes["retries"] <= 3 |
Logical Operators
Important: Use lowercase and, or, not - uppercase operators will cause errors!
| Operator | Description | Example |
|---|---|---|
and | Both conditions must be true | attributes["level"] == "ERROR" and attributes["status"] >= 500 |
or | At least one condition must be true | attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT" |
not | Negates the condition | not IsMatch(attributes["path"], "^/health") |
Regex Matching
| Function | Description | Example |
|---|---|---|
IsMatch | Returns true if string matches the regex pattern | IsMatch(attributes["message"], "ERROR\|FATAL") |
Field Existence Checks
| Check | Description | Example |
|---|---|---|
!= nil | Field exists (not null) | attributes["user_id"] != nil |
== nil | Field doesn’t exist | attributes["optional_field"] == nil |
!= "" | Field is not empty string | attributes["message"] != "" |
Common Examples
nodes:
- name: route_ottl_a72f
type: route_ottl
paths:
# Simple equality check
- path: Frontend-Proxy
condition: resource["service.name"] == "frontend-proxy"
exit_if_matched: true
# Multiple values with OR
- path: security_logs
condition: attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT"
exit_if_matched: true
# Excluding multiple values (NOT equal to multiple values)
- path: non_security_logs
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
exit_if_matched: false
# Complex condition with AND/OR/NOT
- path: critical_errors
condition: (attributes["level"] == "ERROR" or attributes["level"] == "FATAL") and attributes["env"] != "test"
exit_if_matched: true
# Field existence and value check
- path: authenticated_requests
condition: attributes["user_id"] != nil and attributes["user_id"] != ""
exit_if_matched: false
# Regex matching
- path: api_calls
condition: IsMatch(attributes["path"], "^/api/") and not IsMatch(attributes["path"], "^/api/health")
Common Mistakes to Avoid
# WRONG - Cannot use OR/AND with values directly
condition: attributes["log_type"] != "TRAFFIC" OR "THREAT"
# CORRECT - Must repeat the full comparison
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
# WRONG - Uppercase operators
condition: attributes["status"] == "error" AND attributes["level"] == "critical"
# CORRECT - Lowercase operators
condition: attributes["status"] == "error" and attributes["level"] == "critical"
# WRONG - Multi-line conditions
condition: |
attributes["level"] == "ERROR" and
attributes["status"] >= 500
# CORRECT - Single line (even if long)
condition: attributes["level"] == "ERROR" and attributes["status"] >= 500
error_mode
This parameter requires Edge Delta agent version v2.12.0 or higher.
The error_mode parameter controls how errors are handled during condition evaluation. Valid options are:
silent(default) - errors are silently ignored.strict- errors are logged and reported as metrics.
nodes:
- name: route_ottl_a72f
type: route_ottl
error_mode: strict
paths:
- path: Frontend-Proxy
condition: resource["service.name"] == "frontend-proxy"
exit_if_matched: true
Stop If Matched
Optional boolean value. If true, no further paths are evaluated once a match occurs for a path. Defaults to true.
nodes:
- name: route_ottl_a72f
type: route_ottl
paths:
- path: Frontend-Proxy
condition: resource["service.name"] == "frontend-proxy"
exit_if_matched: true
Routing and Linking
Wire each defined path to a destination or downstream processor:
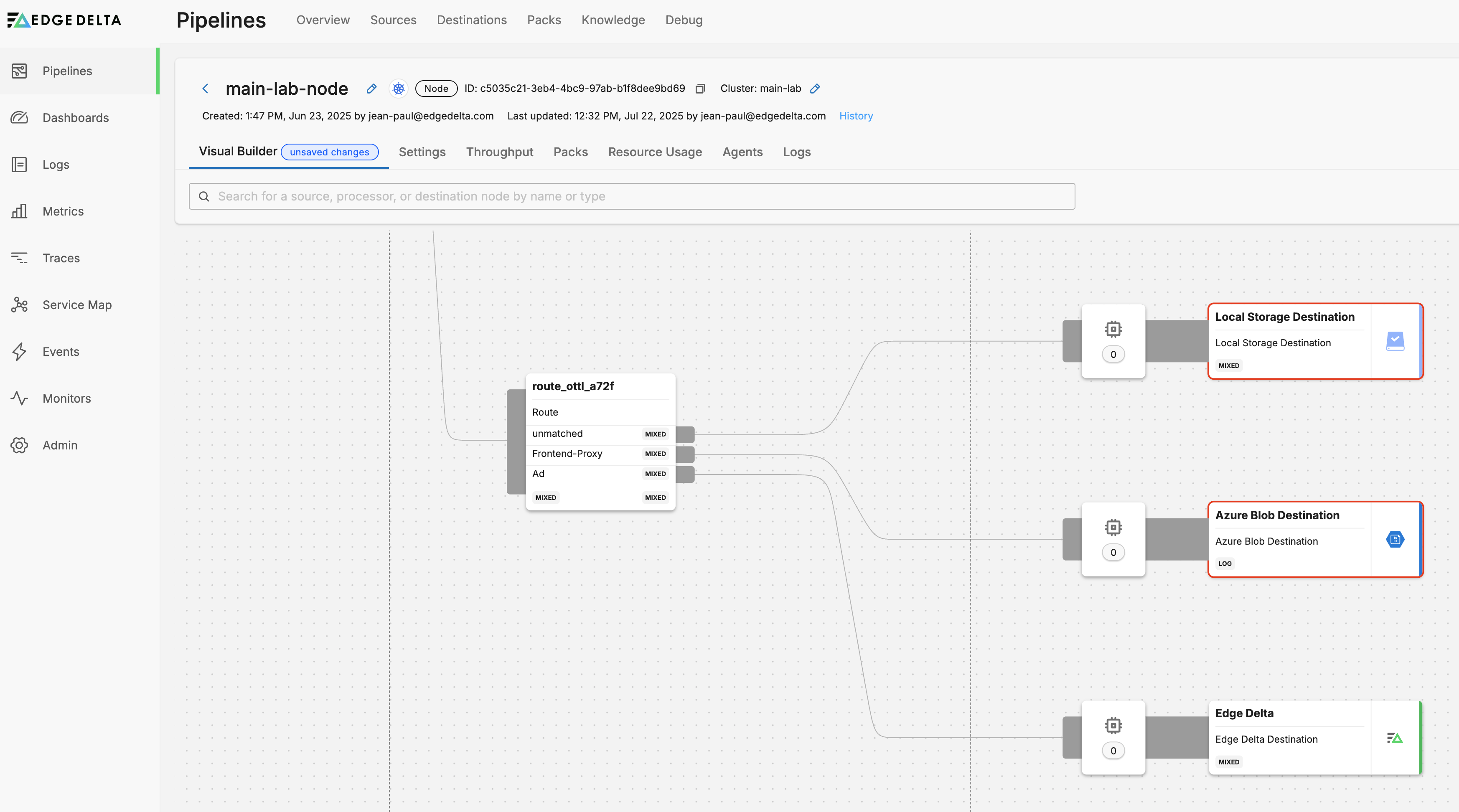
Use the links block to wire each defined path to a destination processor.
links:
- from: route_ottl_a72f
path: unmatched
to: destination001
- from: route_ottl_a72f
path: Frontend-Proxy
to: destination002
- from: route_ottl_a72f
path: Ad
to: destination003
See Also
Configuration Wizard
Use this interactive wizard to generate a starter configuration:
What routing strategy do you want to use?
Choose how items should flow through routing paths.
See Also
- For an overview and to understand processor sequence flow, see Processors Overview
- To learn how to configure a processor, see Configure a Processor.
- For optimization strategies, see Best Practices for Edge Delta Processors.
- If you’re new to pipelines, start with the Pipeline Quickstart Overview or learn how to Configure a Pipeline.
- Looking to understand how processors interact with sources and destinations? Visit the Pipeline Overview.