Edge Delta Parse Timestamp Processor
9 minute read
Overview
There will be a slight difference between the timestamp in a data item body, which is the event time vs the root timestamp field, which is the moment the Edge Delta agent ingested it. See Manage Log Timestamps. You can choose to overwrite the timestamp field using the timestamp in the body, taking into account various timestamp formats. You may need to parse the body first to isolate the timestamp in an attribute.
Use the configuration wizard below to generate a starter YAML configuration.
Use this in Pipeline Quickstart: Use the Log Timestamp.
Example Configuration
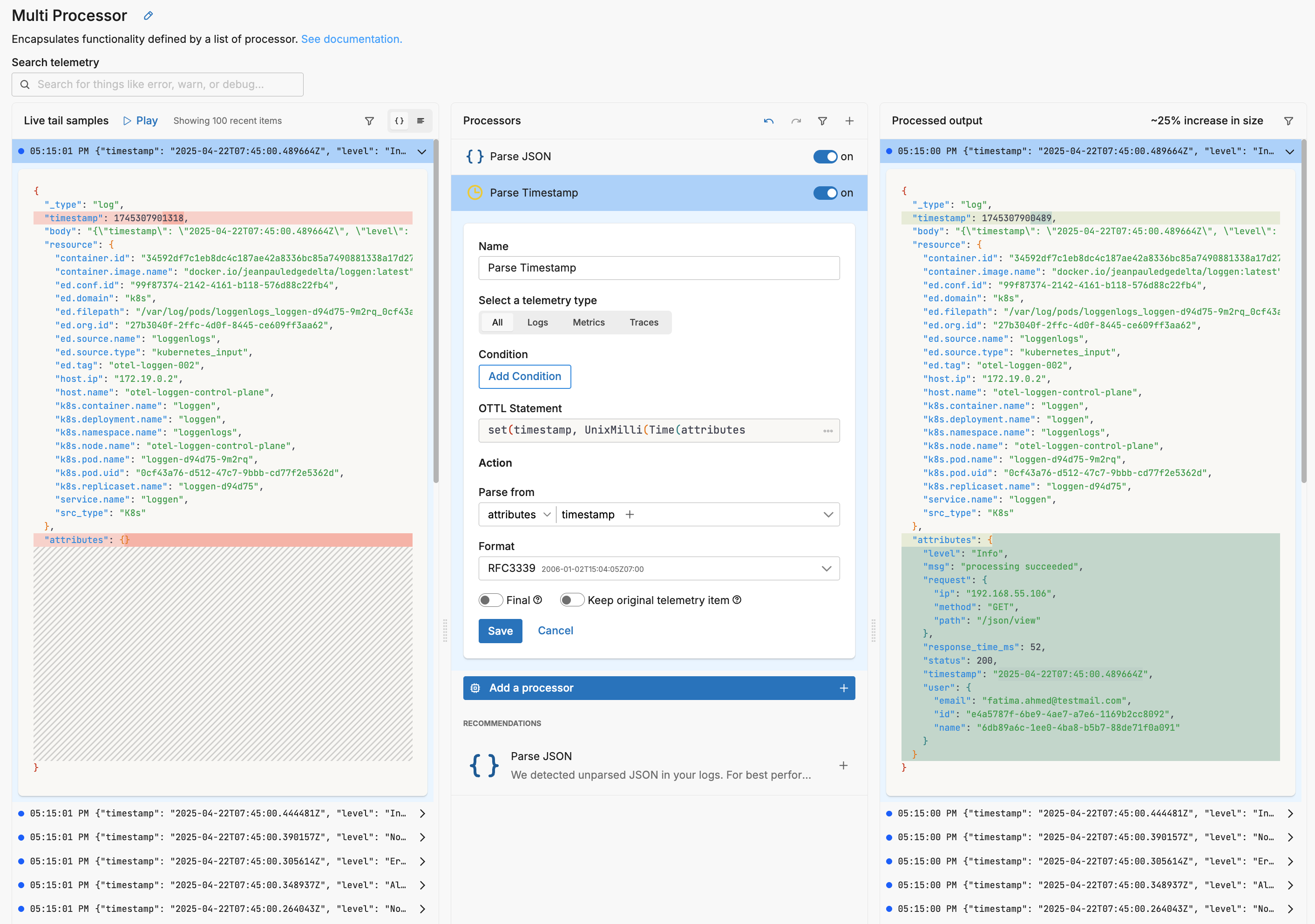
In this example, the timestamp 1745307901318 has been changed to 1745307900489, which is 2025-04-22T07:45:00.489664Z.
YAML version:
- name: Multi Processor
type: sequence
processors:
- type: ottl_transform
metadata: '{"id":"atZl1qvLfkBt-aILGqio_","type":"parse-json","name":"Parse JSON"}'
statements: |-
merge_maps(attributes, ParseJSON(body), "upsert") where IsMap(attributes)
set(attributes, ParseJSON(body)) where not IsMap(attributes)
- type: ottl_transform
metadata: '{"id":"8ywWLkADWPtLOJ2cnpBEU","type":"parse-timestamp","name":"Parse
Timestamp"}'
statements: set(timestamp, UnixMilli(Time(attributes["timestamp"], "2006-01-02T15:04:05Z07:00")))
Options
Select a telemetry type
You can specify, log, metric, trace or all. It is specified using the interface, which generates a YAML list item for you under the data_types parameter. This defines the data item types against which the processor must operate. If data_types is not specified, the default value is all. It is optional.
It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
data_types:
- log
condition
The condition parameter contains a conditional phrase of an OTTL statement. It restricts operation of the processor to only data items where the condition is met. Those data items that do not match the condition are passed without processing. You configure it in the interface and an OTTL condition is generated. It is optional.
Important: All conditions must be written on a single line in YAML. Multi-line conditions are not supported.
Comparison Operators
| Operator | Name | Description | Example |
|---|---|---|---|
== | Equal to | Returns true if both values are exactly the same | attributes["status"] == "OK" |
!= | Not equal to | Returns true if the values are not the same | attributes["level"] != "debug" |
> | Greater than | Returns true if the left value is greater than the right | attributes["duration_ms"] > 1000 |
>= | Greater than or equal | Returns true if the left value is greater than or equal to the right | attributes["score"] >= 90 |
< | Less than | Returns true if the left value is less than the right | attributes["load"] < 0.75 |
<= | Less than or equal | Returns true if the left value is less than or equal to the right | attributes["retries"] <= 3 |
matches | Regex match | Returns true if the string matches a regular expression (generates IsMatch function) | IsMatch(attributes["name"], ".*\\.log$") |
Logical Operators
Important: Use lowercase and, or, not - uppercase operators will cause errors!
| Operator | Description | Example |
|---|---|---|
and | Both conditions must be true | attributes["level"] == "ERROR" and attributes["status"] >= 500 |
or | At least one condition must be true | attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT" |
not | Negates the condition | not IsMatch(attributes["path"], "^/health") |
Functions
| Function | Description | Example |
|---|---|---|
IsMatch | Returns true if string matches the regex pattern | IsMatch(attributes["message"], "ERROR\|FATAL") |
Field Existence Checks
| Check | Description | Example |
|---|---|---|
!= nil | Field exists (not null) | attributes["user_id"] != nil |
== nil | Field doesn’t exist | attributes["optional_field"] == nil |
!= "" | Field is not empty string | attributes["message"] != "" |
Common Examples
- name: _multiprocessor
type: sequence
processors:
- type: <processor type>
# Simple equality check
condition: attributes["request"]["path"] == "/json/view"
- type: <processor type>
# Multiple values with OR
condition: attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT"
- type: <processor type>
# Excluding multiple values (NOT equal to multiple values)
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
- type: <processor type>
# Complex condition with AND/OR/NOT
condition: (attributes["level"] == "ERROR" or attributes["level"] == "FATAL") and attributes["env"] != "test"
- type: <processor type>
# Field existence and value check
condition: attributes["user_id"] != nil and attributes["user_id"] != ""
- type: <processor type>
# Regex matching on attributes
condition: IsMatch(attributes["path"], "^/api/") and not IsMatch(attributes["path"], "^/api/health")
- type: <processor type>
# Regex matching on body (case-insensitive)
condition: IsMatch(body, "(?i)error")
Common Mistakes to Avoid
# WRONG - Cannot use OR/AND with values directly
condition: attributes["log_type"] != "TRAFFIC" OR "THREAT"
# CORRECT - Must repeat the full comparison
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
# WRONG - Uppercase operators
condition: attributes["status"] == "error" AND attributes["level"] == "critical"
# CORRECT - Lowercase operators
condition: attributes["status"] == "error" and attributes["level"] == "critical"
# WRONG - Multi-line conditions
condition: |
attributes["level"] == "ERROR" and
attributes["status"] >= 500
# CORRECT - Single line (even if long)
condition: attributes["level"] == "ERROR" and attributes["status"] >= 500
Parse from
Specify the field containing the timestamp.
Format
Specify the format that the timestamp is currently in. The options show examples so you can match the format. If your format is not listed you can use a golang time configuration. To do this, select Custom as the format. Then enter the following golang reference date in the Custom format field, but format it according to your input timestamp: Mon Jan 2 15:04:05 -0700 MST 2006:
- 1 represents the month (January)
- 2 represents the day of the month
- 3 represents the hour in 12-hour format (3 PM)
- 4 represents the minute
- 5 represents the second
- 6 represents the year (2006)
- -0700 represents the time zone offset
- MST represents the time zone abbreviation
For example, if your format is Time_2013|10|15~05_52_12, you enter Time_2006|01|02~15_04_05 in the Custom format field. The unique values in the reference datetime enable the processor to map the input format.
Error mode
Minimum Agent Version: v2.11.0
Controls how the processor handles parsing errors. Available under Advanced Settings in the UI.
| Mode | Description |
|---|---|
silent | (Default) Suppresses error logs for parsing failures. Use this when parsing errors are expected and don’t require investigation. |
strict | Logs errors when parsing fails. Use this when you need visibility into parsing failures for debugging or validation. |
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
error_mode: silent
Final
Determines whether successfully processed data items should continue through the remaining processors in the same processor stack. If final is set to true, data items output by this processor are not passed to subsequent processors within the node—they are instead emitted to downstream nodes in the pipeline (e.g., a destination). Failed items are always passed to the next processor, regardless of this setting.
The UI provides a slider to configure this setting. The default is false. It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
final: true
Keep original telemetry item
Controls whether the original, unmodified telemetry item is preserved after processing. If keep_item is set to true, the processor emits both:
- The original telemetry item (e.g., a log), and
- Any new item generated by the processor (e.g., a metric extracted from the log)
Both items are passed to the next processor in the stack unless final is also set.
Interaction with final
If final: true is enabled, any successfully processed data items, whether original, newly created, or both, exit the processor stack or node immediately. No subsequent processors within the same node are evaluated, although downstream processing elsewhere in the pipeline continues. This means:
- If
keep_item: trueandfinal: true, both the original and processed items bypass the remaining processors in the current node and are forwarded to downstream nodes (such as destinations). - If
keep_item: falseandfinal: true, only the processed item continues beyond this processor, skipping subsequent processors in the stack, and the original item is discarded.
Note: If the data item fails to be processed, final has no effect, the item continues through the remaining processors in the node regardless of the keep_item setting.
The app provides a slider to configure keep_item. The default is false.
- name: ed_gateway_output_a3fa_multiprocessor
type: sequence
processors:
- type: <processor_type>
keep_item: true
final: true
Configuration Wizard
Use this interactive wizard to generate a starter configuration:
See Also
- For an overview and to understand processor sequence flow, see Processors Overview
- To learn how to configure a processor, see Configure a Processor.
- For optimization strategies, see Best Practices for Edge Delta Processors.
- If you’re new to pipelines, start with the Pipeline Quickstart Overview or learn how to Configure a Pipeline.
- Looking to understand how processors interact with sources and destinations? Visit the Pipeline Overview.