Edge Delta Sample Processor
7 minute read
The Sample Processor enables you to apply consistent probabilistic sampling to telemetry data — logs, traces, and metrics — based on configurable conditions and percentage-based rules. Metric item support requires Edge Delta agent version v2.13.0 or higher. It is designed to reduce data volume while preserving representative data characteristics, which is especially useful for controlling cost and improving observability signal quality.
Learn more: Consistent Probabilistic Sampling in Our Sample Processor Node
Configuration
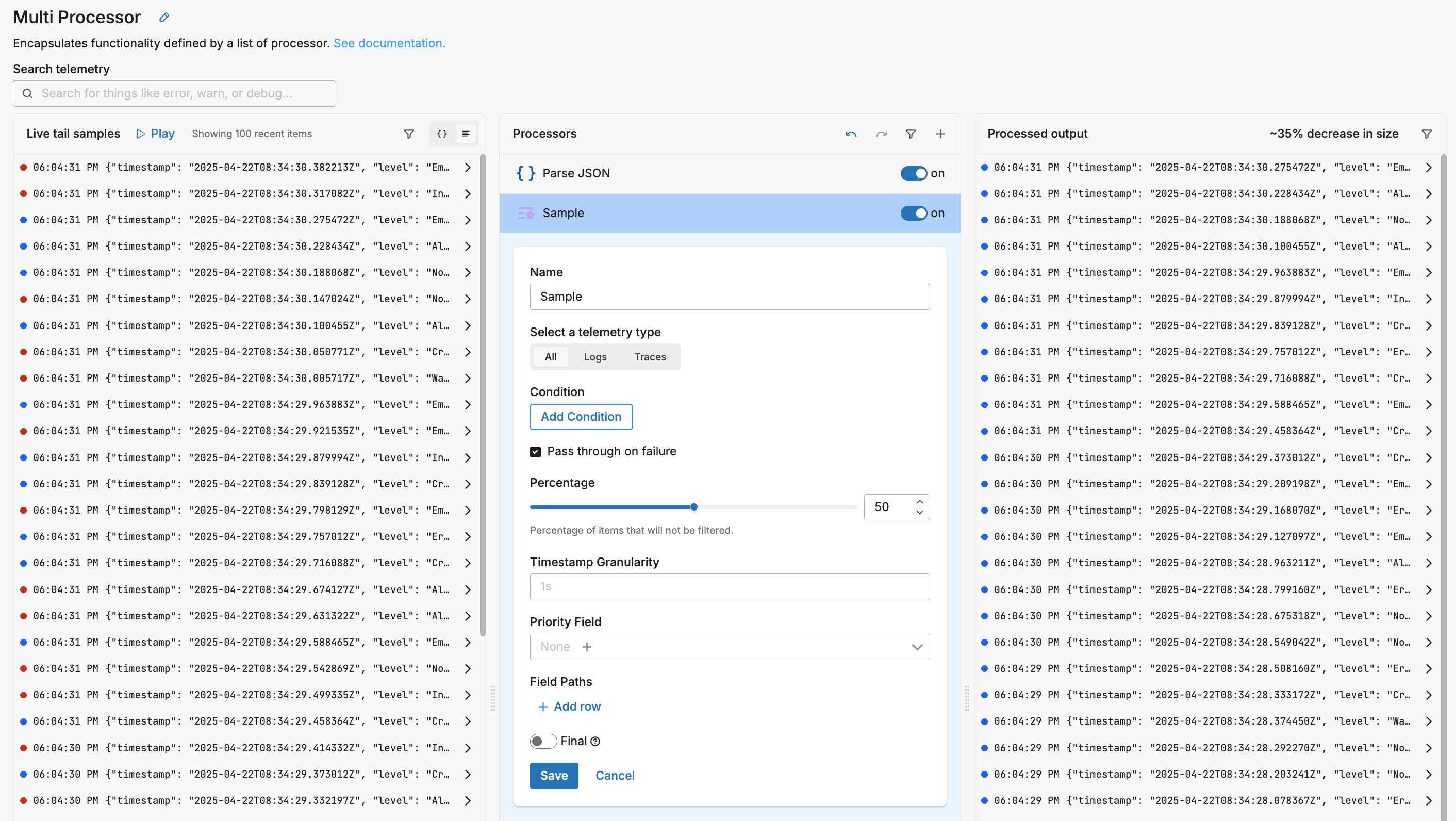
In the example above, 50% of logs are sampled (let through) without regard to content. Sampling behavior is customizable based on field values, timestamp granularity, and dynamic override fields.
nodes:
- name: otlp_input_9cd0_multiprocessor
type: sequence
user_description: Multi Processor
processors:
- type: sample
metadata: '{"id":"12456789","type":"sample","name":"Sample"}'
data_types:
- log
percentage: 50
pass_through_on_failure: true
Options
Select a telemetry type
You can specify, log, metric, trace or all. It is specified using the interface, which generates a YAML list item for you under the data_types parameter. This defines the data item types against which the processor must operate. If data_types is not specified, the default value is all. It is optional.
It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
data_types:
- log
condition
The condition parameter contains a conditional phrase of an OTTL statement. It restricts operation of the processor to only data items where the condition is met. Those data items that do not match the condition are passed without processing. You configure it in the interface and an OTTL condition is generated. It is optional.
Important: All conditions must be written on a single line in YAML. Multi-line conditions are not supported.
Comparison Operators
| Operator | Name | Description | Example |
|---|---|---|---|
== | Equal to | Returns true if both values are exactly the same | attributes["status"] == "OK" |
!= | Not equal to | Returns true if the values are not the same | attributes["level"] != "debug" |
> | Greater than | Returns true if the left value is greater than the right | attributes["duration_ms"] > 1000 |
>= | Greater than or equal | Returns true if the left value is greater than or equal to the right | attributes["score"] >= 90 |
< | Less than | Returns true if the left value is less than the right | attributes["load"] < 0.75 |
<= | Less than or equal | Returns true if the left value is less than or equal to the right | attributes["retries"] <= 3 |
matches | Regex match | Returns true if the string matches a regular expression (generates IsMatch function) | IsMatch(attributes["name"], ".*\\.log$") |
Logical Operators
Important: Use lowercase and, or, not - uppercase operators will cause errors!
| Operator | Description | Example |
|---|---|---|
and | Both conditions must be true | attributes["level"] == "ERROR" and attributes["status"] >= 500 |
or | At least one condition must be true | attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT" |
not | Negates the condition | not IsMatch(attributes["path"], "^/health") |
Functions
| Function | Description | Example |
|---|---|---|
IsMatch | Returns true if string matches the regex pattern | IsMatch(attributes["message"], "ERROR\|FATAL") |
Field Existence Checks
| Check | Description | Example |
|---|---|---|
!= nil | Field exists (not null) | attributes["user_id"] != nil |
== nil | Field doesn’t exist | attributes["optional_field"] == nil |
!= "" | Field is not empty string | attributes["message"] != "" |
Common Examples
- name: _multiprocessor
type: sequence
processors:
- type: <processor type>
# Simple equality check
condition: attributes["request"]["path"] == "/json/view"
- type: <processor type>
# Multiple values with OR
condition: attributes["log_type"] == "TRAFFIC" or attributes["log_type"] == "THREAT"
- type: <processor type>
# Excluding multiple values (NOT equal to multiple values)
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
- type: <processor type>
# Complex condition with AND/OR/NOT
condition: (attributes["level"] == "ERROR" or attributes["level"] == "FATAL") and attributes["env"] != "test"
- type: <processor type>
# Field existence and value check
condition: attributes["user_id"] != nil and attributes["user_id"] != ""
- type: <processor type>
# Regex matching on attributes
condition: IsMatch(attributes["path"], "^/api/") and not IsMatch(attributes["path"], "^/api/health")
- type: <processor type>
# Regex matching on body (case-insensitive)
condition: IsMatch(body, "(?i)error")
Common Mistakes to Avoid
# WRONG - Cannot use OR/AND with values directly
condition: attributes["log_type"] != "TRAFFIC" OR "THREAT"
# CORRECT - Must repeat the full comparison
condition: attributes["log_type"] != "TRAFFIC" and attributes["log_type"] != "THREAT"
# WRONG - Uppercase operators
condition: attributes["status"] == "error" AND attributes["level"] == "critical"
# CORRECT - Lowercase operators
condition: attributes["status"] == "error" and attributes["level"] == "critical"
# WRONG - Multi-line conditions
condition: |
attributes["level"] == "ERROR" and
attributes["status"] >= 500
# CORRECT - Single line (even if long)
condition: attributes["level"] == "ERROR" and attributes["status"] >= 500
Pass through on failure
If enabled, logs are passed through the pipeline even when an error occurs during evaluation (e.g., malformed field, type mismatch). This prevents data loss due to misconfigurations.
nodes:
- name: otlp_input_9cd0_multiprocessor
type: sequence
processors:
- type: sample
pass_through_on_failure: true
Percentage
Defines the baseline percentage of data items to allow through the node. For example, setting this to 50 means 50% of matching logs or traces will pass through.
If a Sample Rate Override field is defined and present on an item, its value will override this percentage for that item.
nodes:
- name: otlp_input_9cd0_multiprocessor
type: sequence
processors:
- type: sample
percentage: 50
Timestamp granularity
Specifies the resolution for timestamp grouping when determining sample consistency.
- Used to define sameness when no
Field Pathsare specified. - Default sampling keys for logs:
(timestamp, service.name, body). - Granularity must be ≥ 1 millisecond.
- Common use:
1s,1m,100ms
This value affects whether logs are considered “the same” during hashing for consistent sampling. If too coarse (e.g., 1m), many different logs may hash the same, leading to unintended sampling bias.
Sample Rate Override
A field path used to dynamically control the sampling percentage on a per-item basis. This field should contain a numeric value from 0 to 100 (as a string or number).
If present in the data item, this value overrides the default Percentage.
Field paths
A list of field paths that define what values to use when computing the hash for sampling. These values define what constitutes “sameness” across items and impact consistency.
If no field paths are specified, the default sampling fields are:
- Logs:
timestamp,service.name,body - Traces:
trace_id - Metrics:
timestamp,service.name,metric_name
Use this option when sampling needs to be based on other attributes such as a cluster attribute or custom tags.
Final
Determines whether successfully processed data items should continue through the remaining processors in the same processor stack. If final is set to true, data items output by this processor are not passed to subsequent processors within the node—they are instead emitted to downstream nodes in the pipeline (e.g., a destination). Failed items are always passed to the next processor, regardless of this setting.
The UI provides a slider to configure this setting. The default is false. It is defined in YAML as follows:
- name: multiprocessor
type: sequence
processors:
- type: <processor type>
final: true
Known Limitation
If the Sample Rate Override field is used but the values in the item do not vary across logs (e.g., all are set to 100), then sampling behavior will default to allowing all items through. Additionally, consistent sampling relies on the sameness of hashed values. If timestamp granularity or default sampling fields (timestamp, service.name, body) don’t vary enough, this may result in sampling behavior that appears static.
Best Practices and Troubleshooting
Sample Rate Override Not Working?
- Ensure the override field exists in all target items.
- Its value is numeric (or a stringified number) between
0and100. - The timestamp granularity and field paths are appropriate for the log’s structure and rate of change.
- The field is not empty, malformed, or missing from sampled logs.
Volume Doesn’t Fluctuate?
Consistent sampling hashes the same values for identical data. If the default sampling keys don’t vary enough, especially with a coarse Timestamp Granularity (like 1m), sampling will appear static.
Solutions:
- Lower the
Timestamp Granularityto1sor100ms. - Specify unique
Field Paths(e.g.,user_idattribute). - Confirm the
ratevalue changes per event if usingSample Rate Override.
See Also
- For an overview and to understand processor sequence flow, see Processors Overview
- To learn how to configure a processor, see Configure a Processor.
- For optimization strategies, see Best Practices for Edge Delta Processors.
- If you’re new to pipelines, start with the Pipeline Quickstart Overview or learn how to Configure a Pipeline.
- Looking to understand how processors interact with sources and destinations? Visit the Pipeline Overview.