Integrate Edge Delta's Node, Coordinator, and Gateway Pipelines
13 minute read
Overview
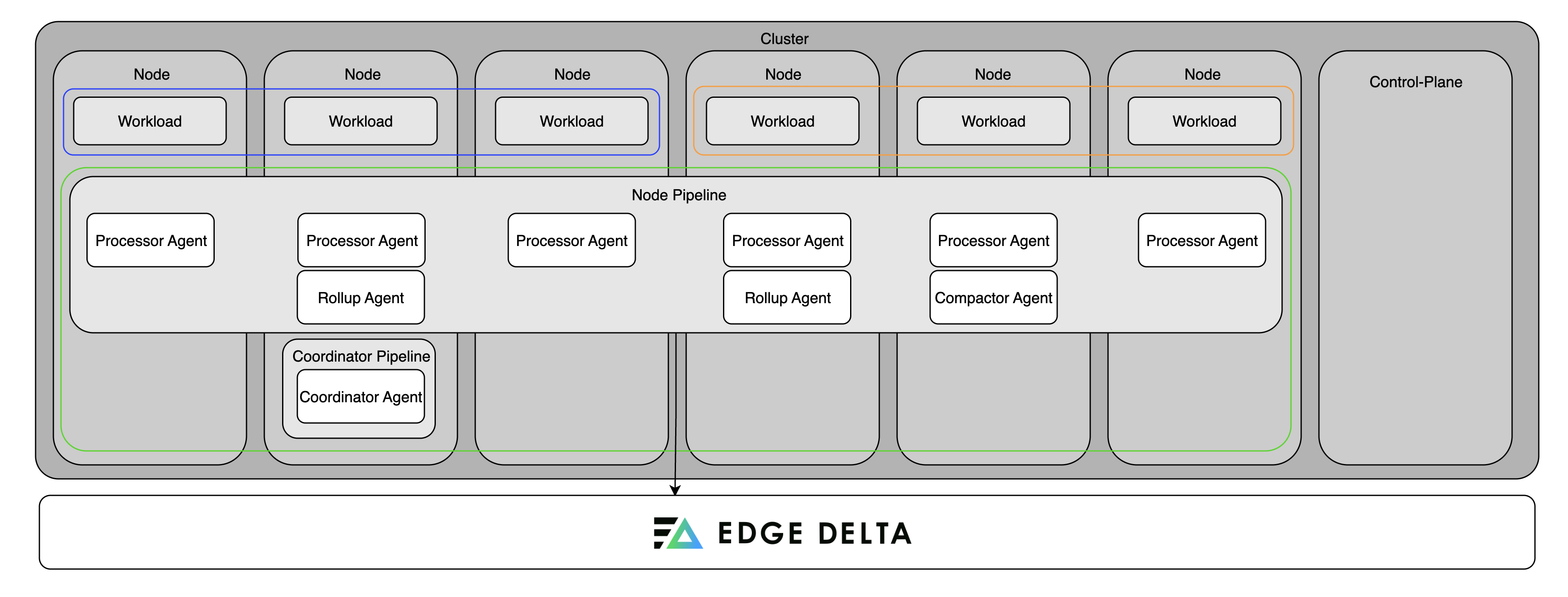
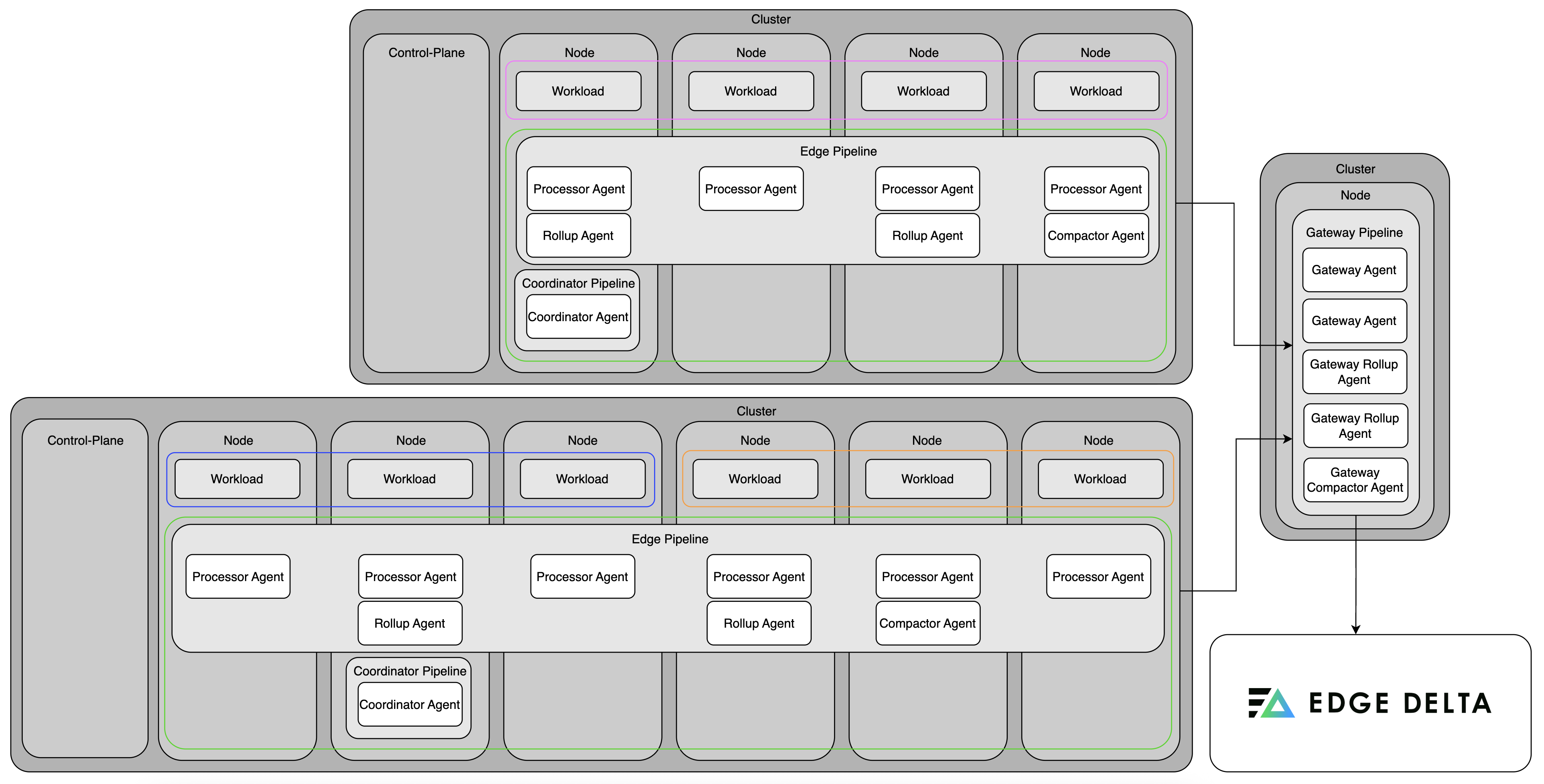
Edge Delta pipelines work together to process telemetry data efficiently in Kubernetes environments. You deploy the node pipeline directly on your infrastructure, such as within Kubernetes clusters. These agents run close to the data source, allowing them to process logs and metrics immediately. They extract insights, generate alerts, compress and roll up data, and then send the output to the Edge Delta Observability Platform or other destinations.
Use the gateway pipeline to collect and process data from multiple node agents or external sources. It aggregates metrics, removes duplicate logs, and supports service-level views. You can deploy multiple gateway agents to scale processing as needed. Connect node and gateway pipelines using matching gateway input and output nodes.
Tail sampling enables you to decide whether to retain or drop a trace after seeing the entire set of spans that make it up. In a distributed environment, each node pipeline collects only a subset of spans, making trace-level sampling impossible at the agent level. By routing all spans to a gateway pipeline, which buffers and processes them centrally, you can apply tail sampling logic to complete traces.
The coordinator pipeline manages communication between node agents within the cluster. It also coordinates gateway pipelines within the same namespace. It handles control signals from the backend, reduces redundant data collection, and uses the Kubernetes API to discover and organize agents. Deploy one coordinator per cluster in the same namespace as the node pipeline.
A coordinator is required for live tail to work in clusters with more than 20 nodes. For smaller clusters, a coordinator is optional but recommended for production deployments—it reduces backend overhead and improves live capture coverage across nodes.
See:
- Edge Delta Architecture - Pipeline types and organization
- Kubernetes Deployment Examples
- Edge Delta Pipeline Source
- Edge Delta Gateway Connection
- Monitoring and Visibility - Track pipeline health
Logical Grouping
The first aspect of pipeline integration is the Kubernetes Cluster Name you specify when creating the pipelines.
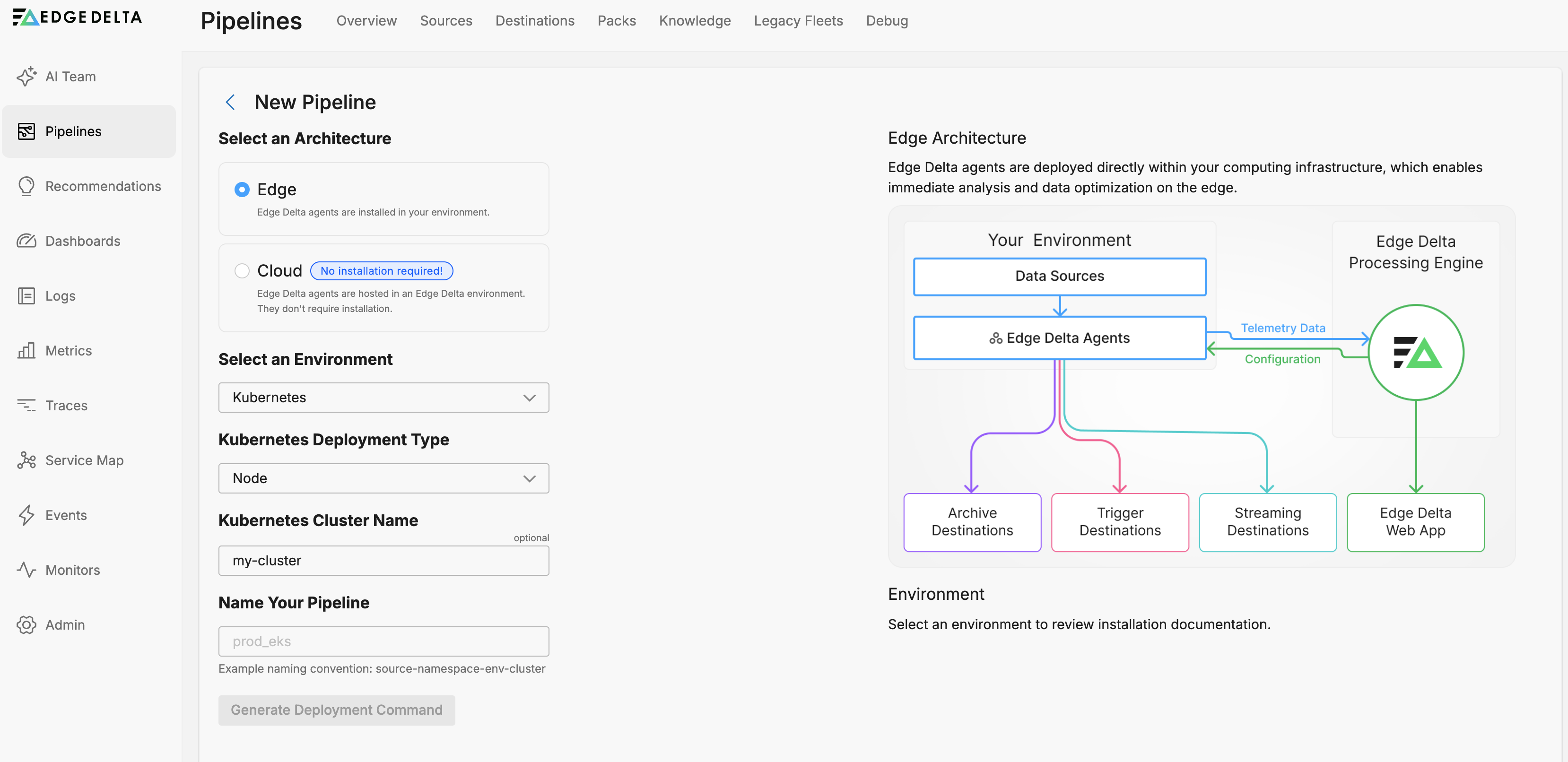
This typically refers to a common cluster that the pipelines are installed in, but it can be used to logically group pipelines that are in different clusters. You can view the pipelines grouped together in the pipelines table:
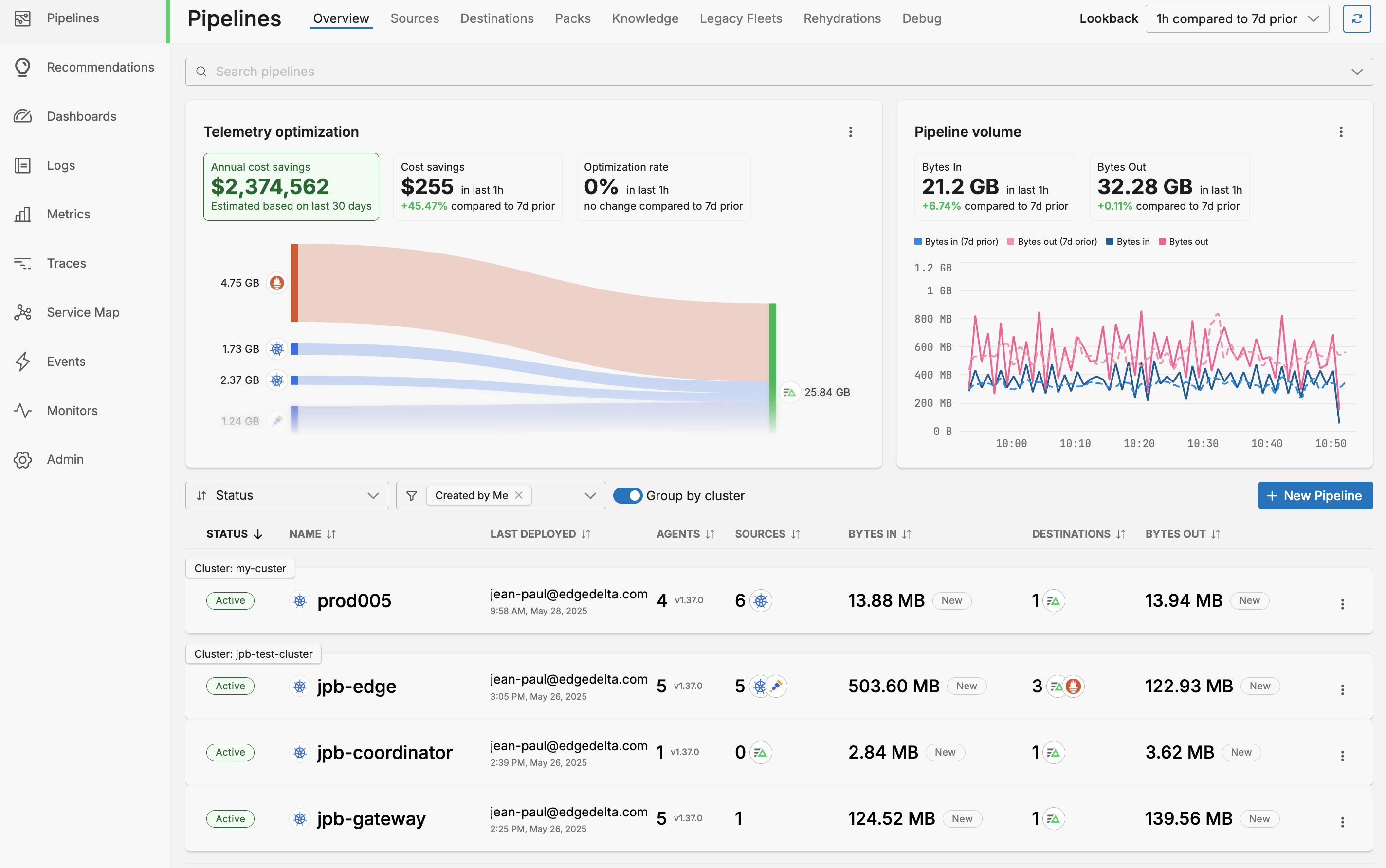
The Group by cluster option is enabled. In this instance there are two groups. One contains just a node cluster prod005, the other contains a node, coordinator and gateway cluster.
The cluster name becomes a resource field in your data items and you can search for data items with that resource:
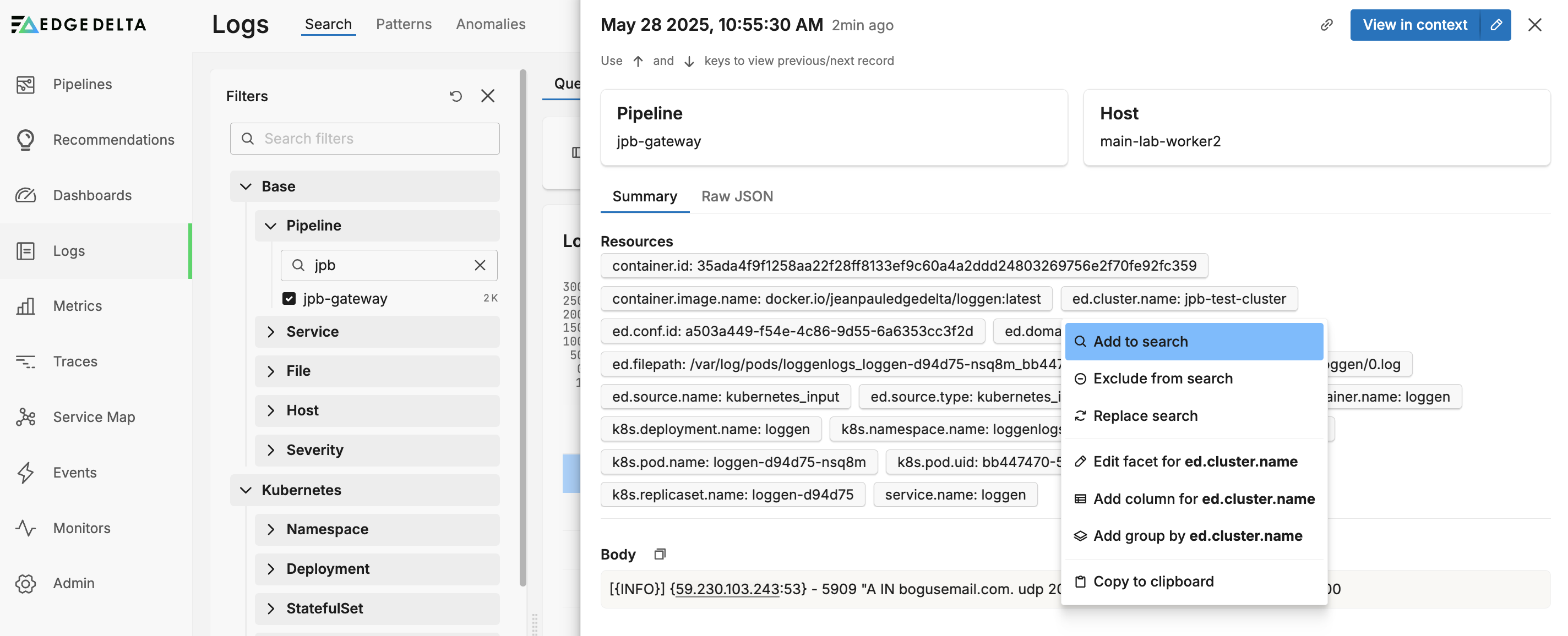
This will add ed.cluster.name:"jpb-test-cluster" to the search string.
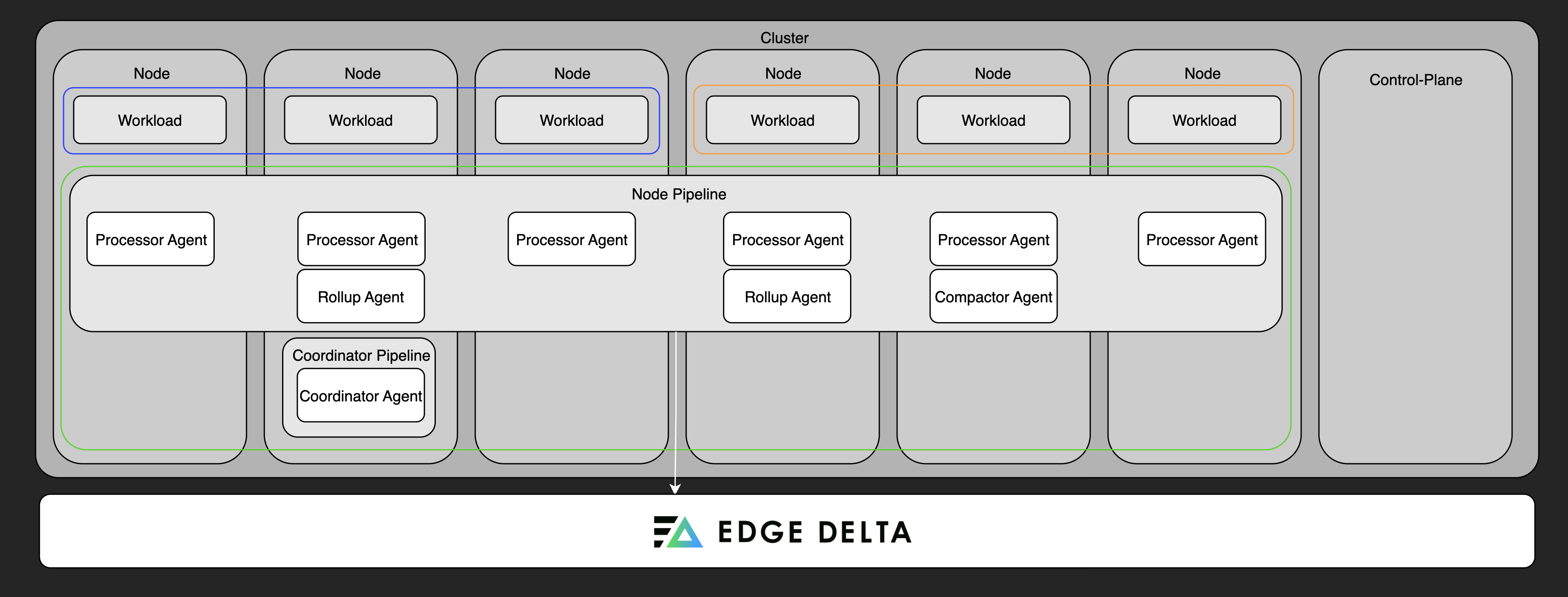
Integrating a Coordinator with a Node Pipeline
The coordinator pipeline doesn’t require any manual integration or setup. Once installed, it automatically discovers Edge Delta agents in the same Kubernetes namespace using the Kubernetes API and begins coordinating them.
In large Kubernetes clusters, where a node pipeline deploys processor agents as a DaemonSet (so all nodes share the same pipeline configuration), direct communication between each agent and the cloud backend can quickly become inefficient. As the number of nodes increases, features like live log tailing or cluster-wide data aggregation can become slow or unreliable due to the high volume of direct backend interactions.
By deploying a single coordinator pipeline, you shift coordination tasks to a dedicated control-plane agent. The coordinator handles backend communication on behalf of the node agents, managing heartbeats, control messages, and live feature orchestration. It also performs tasks like leader election for the processor agents, ensuring only one node executes certain centralized logic. This setup reduces network overhead, speeds up agent–backend interactions, and improves the scalability and responsiveness of observability features across the cluster.
Integrating a Node Pipeline with a Gateway Pipeline
How you integrate the node and gateway pipelines depends on your deployment:
- node pipeline and gateway in the same cluster, or
- gateway in a different cluster or host
Fleet and Gateway in the same cluster
In this setup, the node and gateway pipelines are deployed in the same Kubernetes cluster.
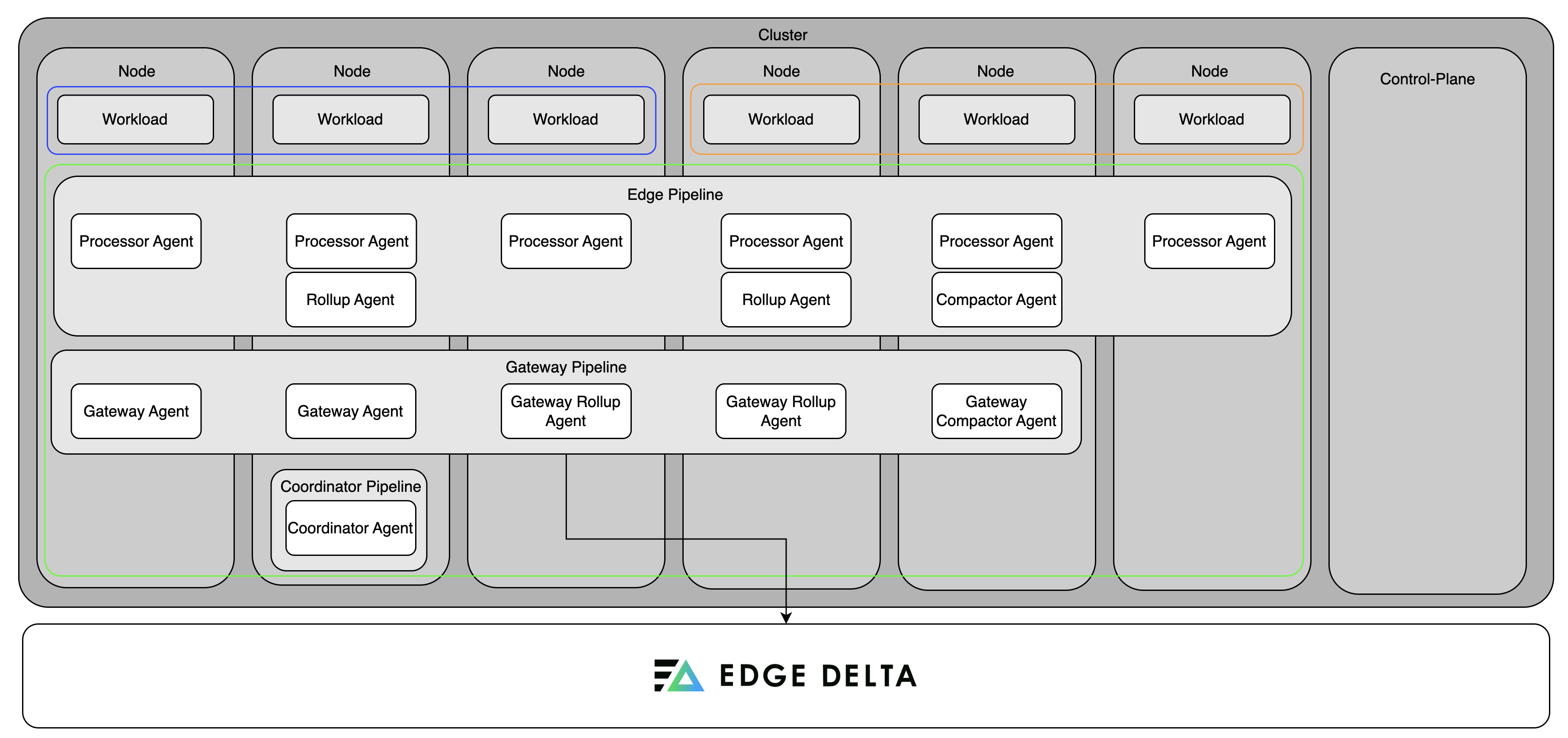
The node pipeline connects to the gateway via the gateway’s headless service, which is discovered automatically. This is the simplest and most common scenario in Kubernetes.
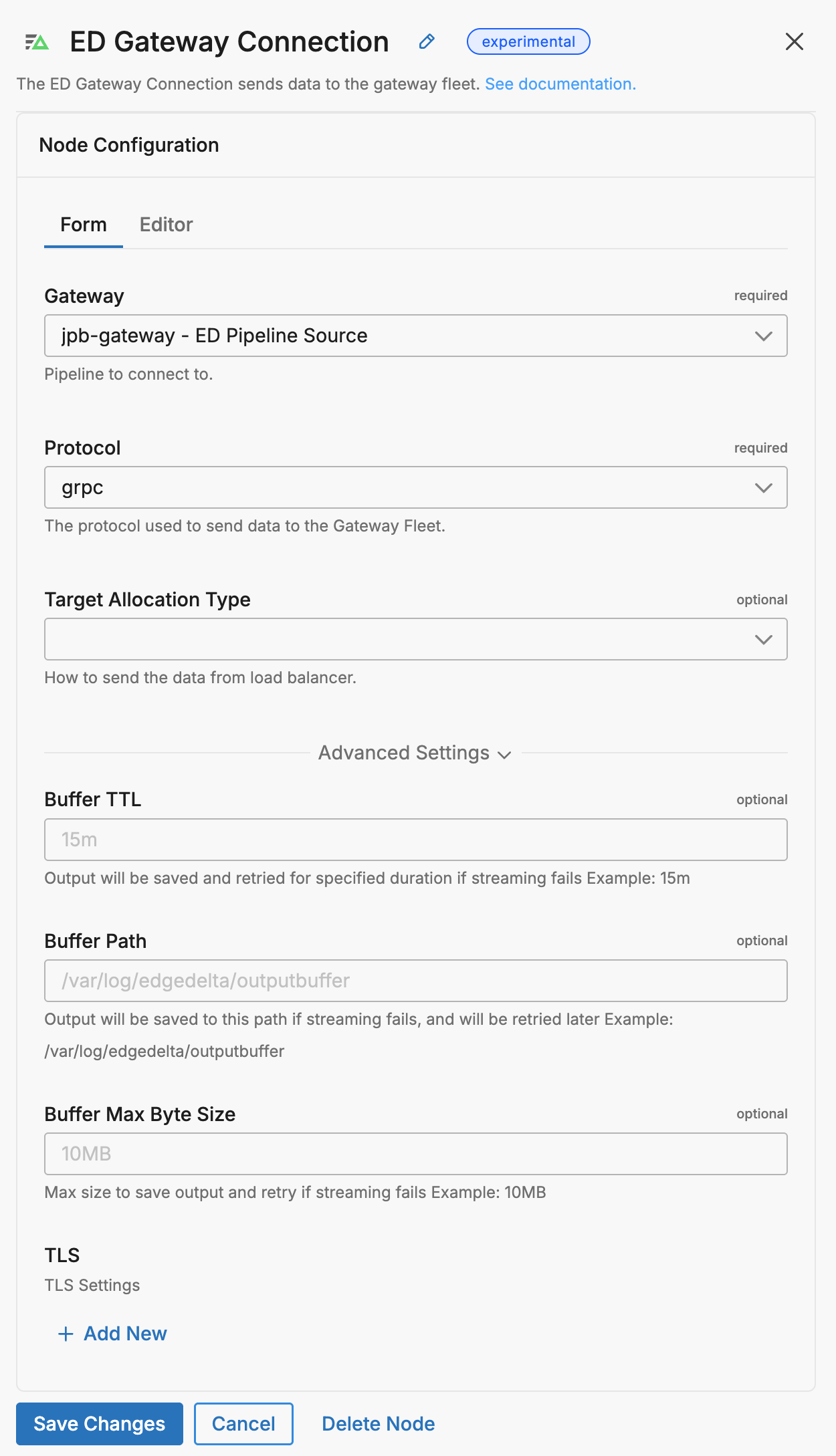
Configure the Gateway Pipeline
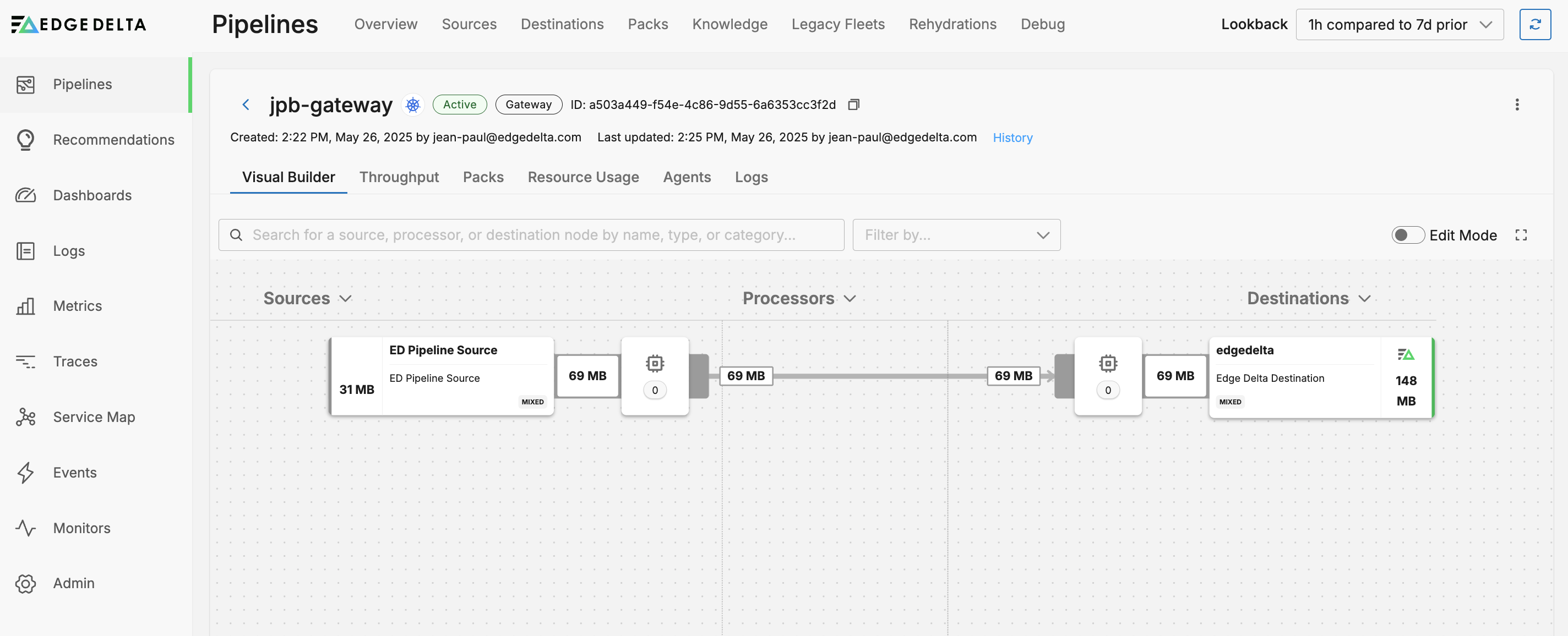
When you deploy a gateway pipeline, an ED Pipeline Source node is added to the configuration, and configured to listen on port 4319 for gRPC traffic by default. If you are connecting it to a node pipeline in the same Kubernetes Cluster, this configuration does not need to change.
Configure the Node Pipeline
Open the node pipeline builder.
Turn on Edit mode.
Add the Gateway Connection destination node.
Select the gateway pipeline name with the appropriate gateway source node name (if it has more than one input) from the Gateway list.
Configure the
target_allocation_typeparameter based on your needs:- Use
consistent(default) for metric aggregation and deduplication across sources - Use
round_robinfor simple load distribution
Note: For multi-cluster deployments, see Multi-Source Cluster Behavior with Consistent Routing for important routing considerations.
- Use
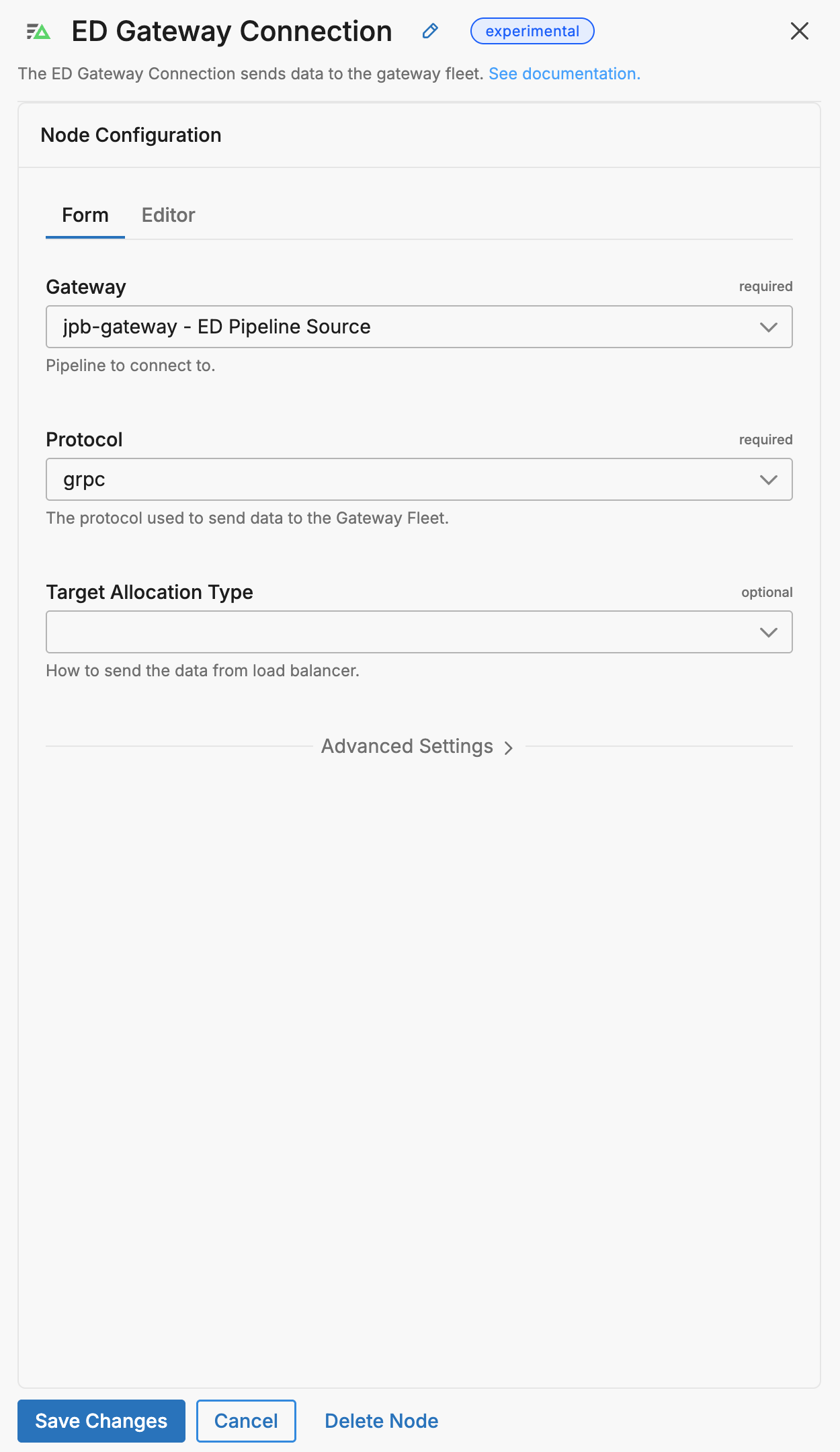
- Click Save Changes.
Gateway in a different cluster or host
Here, the node pipeline and gateway pipeline are deployed in different Kubernetes clusters or on different hosts.
You can use DNS or a static IP to connect to the gateway.
Note: The Gateway Connection destination is available for all OS environment types. For Kubernetes edge pipelines, the gateway appears in an auto-populated dropdown list in the pipeline builder. For non-Kubernetes OS environments (Linux, Windows), the Gateway Connection destination is available but requires manual configuration using Custom settings with DNS or static endpoints (such as via Kubernetes Ingress or NodePort).
Configure the Node Pipeline
DNS
The node pipeline connects using a DNS hostname that resolves to the gateway’s address. Use this when the gateway is exposed via an Ingress, LoadBalancer, or public DNS name.
- Open the node pipeline builder
- Turn on edit mode
- Add the Gateway Connection destination node.
- Select
Customin the Gateway field. - Select
DNSfor the Endpoint Resolution Type. - Specify one or more gateway Hostnames: Public or internal DNS name pointing to the gateway.
- Optionally, specify an interval: How often the agent re-resolves DNS, helpful if using a dynamic load balancer
- Specify the Pipeline you want to associate the node with in the UI.
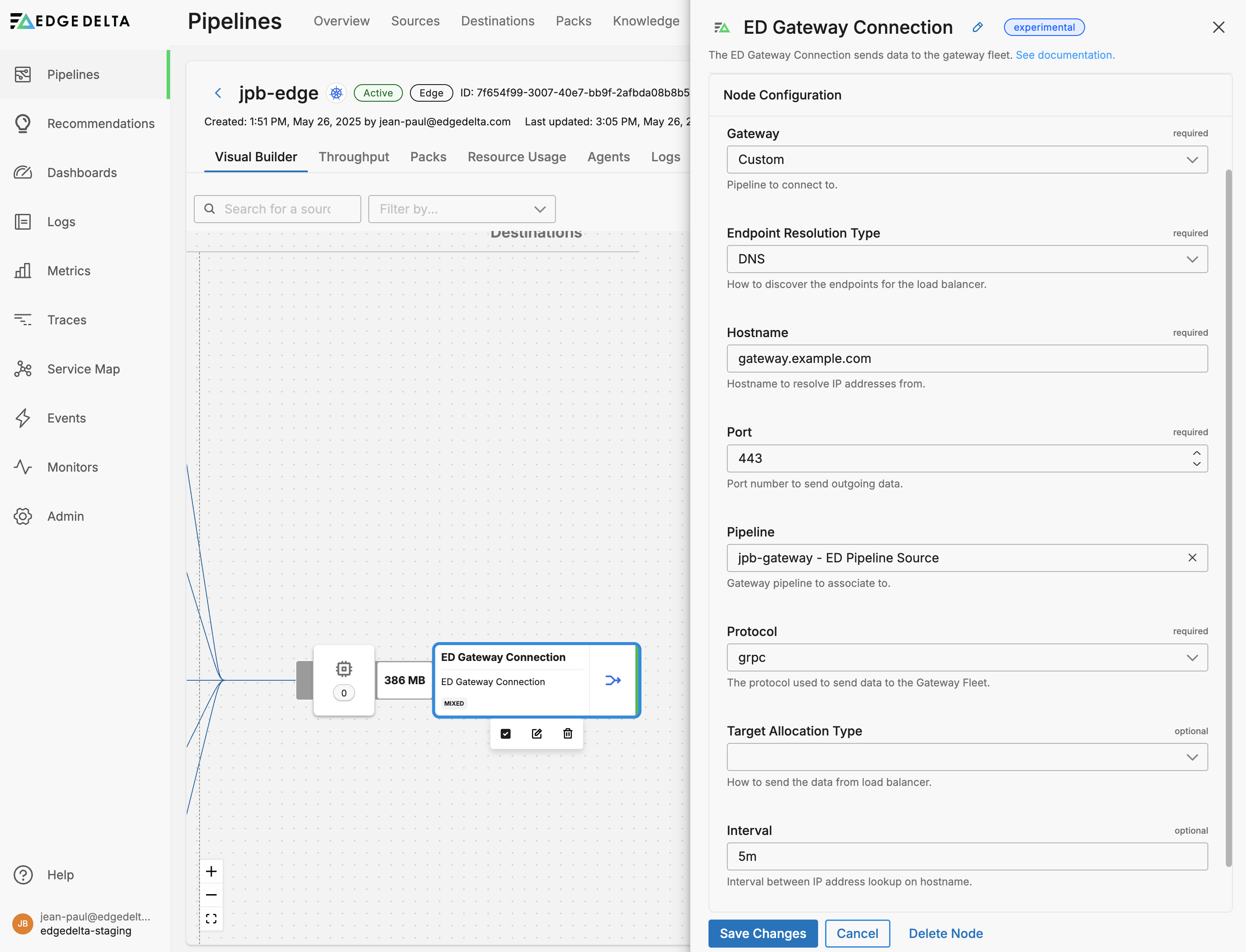
- Click Save Changes.
Static IP
In this case, the node pipeline connects to the gateway using a fixed IP address. This is useful in static environments or where DNS is not available or desired.
- Open the node pipeline builder
- Turn on edit mode
- Add the Gateway Connection destination node.
- Select
Customin the Gateway field. - Select
Staticfor the Endpoint Resolution Type. - Specify one or more Endpoints: IPs or URLs for gateway instances
- Specify the Pipeline you want to associate the node with in the UI.
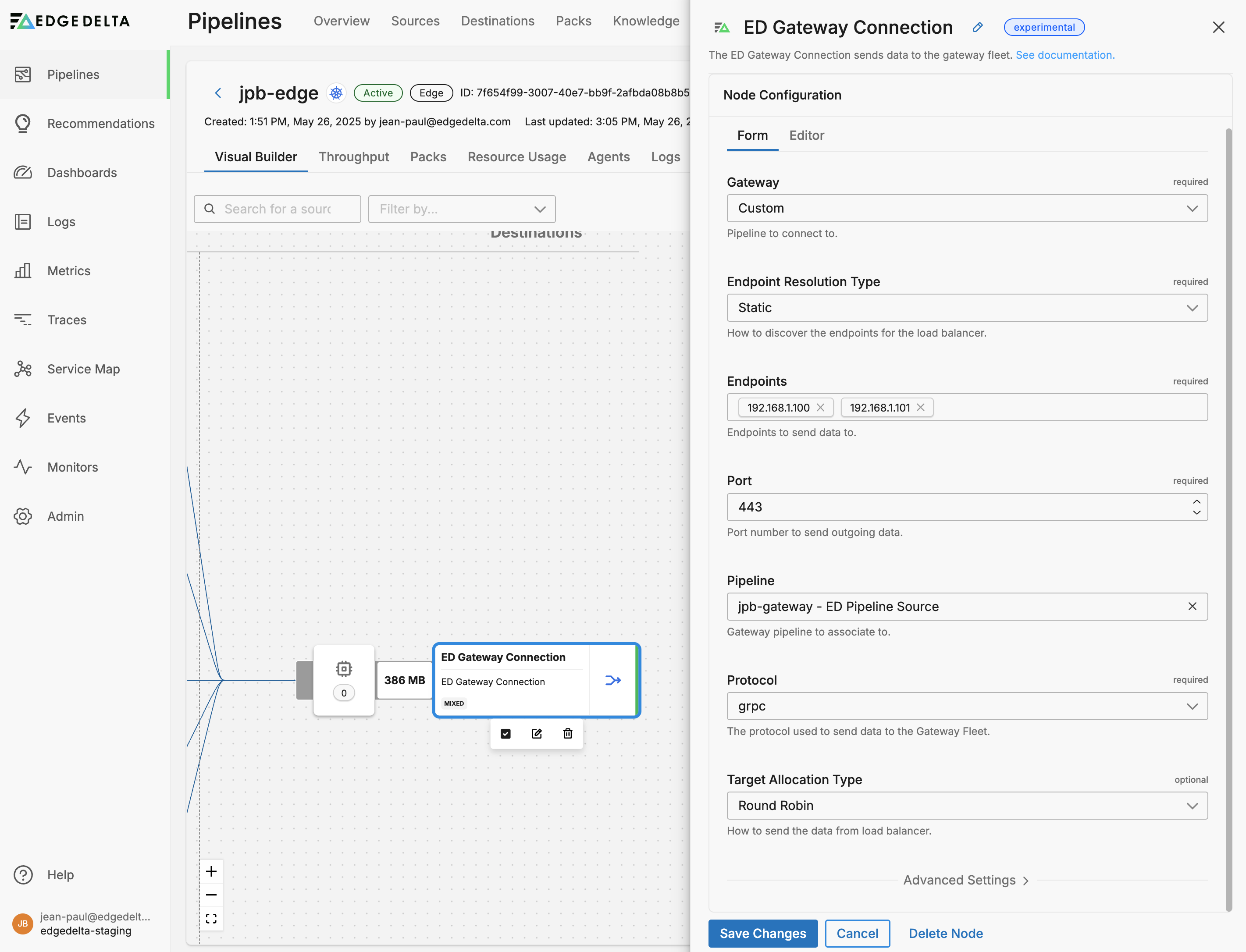
- Click Save Changes.
Configure the Gateway Pipeline
When the node pipeline and gateway pipeline are deployed in different clusters, the node pipeline sends data over a public or private network using either DNS names or static IP addresses. In this scenario, the gateway must be externally reachable, typically through a Kubernetes Ingress or LoadBalancer service.
The gateway’s ED Pipeline Source node must be configured to accept external gRPC or HTTP traffic in a way that aligns with how it’s exposed:
- The port field should match the internal port that the gateway container listens on.
- The Kubernetes service (LoadBalancer, Ingress, or NodePort) should expose that internal port to the outside world.
- TLS settings should reflect where TLS termination occurs, either in the gateway itself or at the ingress layer.
Balancing Traffic
When deploying multiple Edge Delta gateway instances, it’s important to understand how traffic is distributed to them especially in the context of Kubernetes networking.
Kubernetes Services (e.g., ClusterIP or LoadBalancer) provide effective load balancing for data pipelines. However, Kubernetes load balancing occurs at the TCP connection level. The node pipeline implements application-layer routing logic.
To set the Target Allocation Type, specify it in the Gateway Connection destination node of the node pipeline. It lets you control traffic distribution using the target_allocation_type parameter. This supports two modes: consistent and round_robin. Each is evaluated at the application level to give you control over telemetry routing beyond what Kubernetes or network-level load balancers provide.
Use the wizard below to determine the best allocation type for your deployment:
What type of processing will your gateway perform?
This determines whether related telemetry must reach the same gateway instance.
Consistent
Use consistent allocation when correlated data (like logs for the same service or spans for the same trace) must be routed to the same destination. This ensures data locality, which is critical for:
- Trace tail sampling (requires full trace context)
- Log or metric deduplication
- Aggregations by service, tenant, or region
By default, the node pipeline uses these fields to group data:
- Logs, metrics, and events:
service.name - Traces:
trace_id
You can override the grouping logic using the routing_key_expressions field. This supports OTTL-based expressions to define custom keys such as combinations of tenant ID, region, or cluster name.
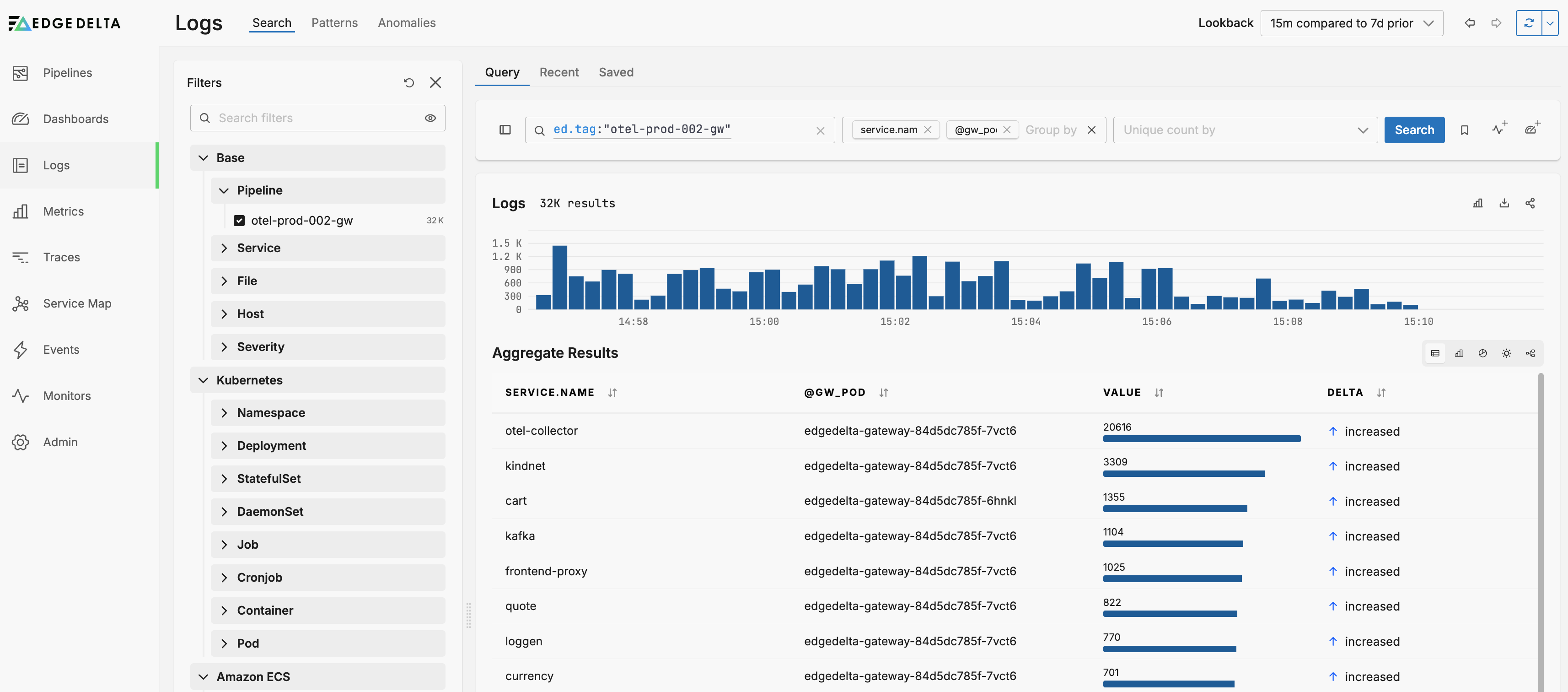
This example uses consistent allocation. The otel-collector service’s traffic is sent only to gateway pod edgedelta-gateway-84d5dc785f-7vct6, while cart traffic is sent only to gateway pod edgedelta-gateway-84d5dc785f-6hnkl.
Note: If your gateway pipeline is exposed behind a standard Kubernetes LoadBalancer or Ingress backed by a network load balancer (NLB), traffic distribution occurs at the TCP connection level. This means that even with consistent allocation configured at the node pipeline, the traffic may still be routed arbitrarily between gateway pods, defeating the purpose of consistent routing. For true application-level load balancing, where each request is evaluated independently, an Application Load Balancer (ALB) can be used.
Bear in mind that consistent allocation might cause one destination to be more heavily used than another as one service creates more traffic than another. So you need to consider gateway scaling.
routing_key_expressions
This option overrides default routing behavior using OTTL-based expressions. This is useful when advanced routing logic is required—for example, distributing logs based on tenant ID, environment, or region. Use this parameter to ensure that data is consistently routed according to key fields in the telemetry payload.
The routing_key_expressions parameter is only relevant when target_allocation_type is set to consistent. It customizes how consistency is calculated, not whether consistency is used.
For example, you might create a parameter upstream that concatenates service name and cluster name, and use that as a routing key expression. In this instance, all traffic with the same service-cluster name will be routed to the same destination gateway.
Round Robin
Round Robin allocation evenly distributes data across all gateway instances regardless of source. Use this when your processing is stateless or does not require correlated data.
Round Robin is appropriate when:
- You are only dropping or transforming data based on independent fields
- You want to offload compute from the edge to the gateway, but do not require data locality
- The backend or destination will perform final aggregation or grouping
This is more efficient and requires less coordination, but sacrifices the ability to correlate, count, or sample by logical grouping.
If you are unsure which option to use, ask: Do I need related telemetry to reach the same destination for accurate processing? If yes, use consistent. If no, use round_robin for simplicity and efficiency.
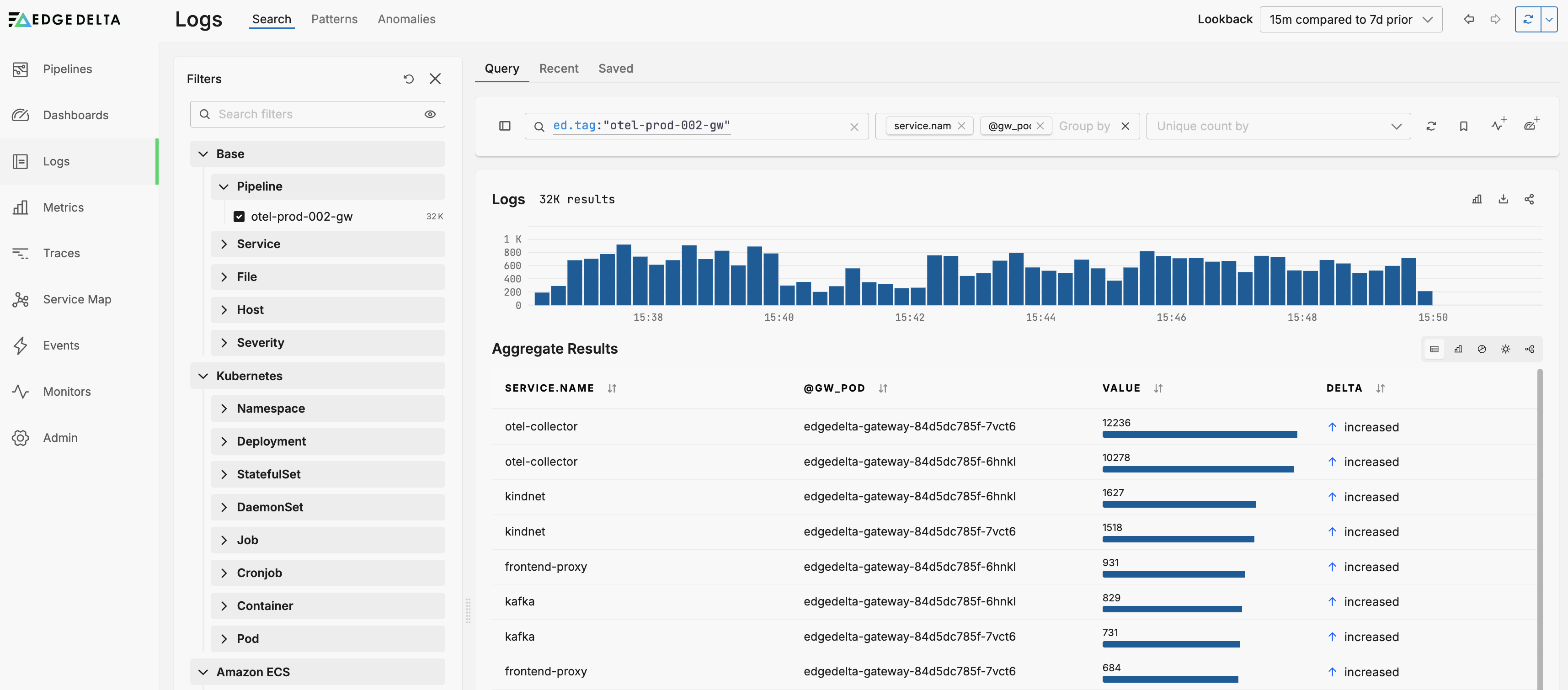
This example uses round_robin allocation. The otel-collector service’s traffic (and all services’ traffic) is evenly distributed across both gateway pods edgedelta-gateway-84d5dc785f-7vct6 and edgedelta-gateway-84d5dc785f-6hnkl.
Circuit Breaker and Fallback Impact
If the circuit breaker is enabled in the gateway connection node, traffic balancing behavior may be affected during failures:
- Consistent allocation respects routing keys, but if the targeted gateway is unhealthy, fallback strategies may override it.
- Fallback strategies include:
- Reroute: Retry up to 3 healthy destinations.
- Health-Based Sampling: Preserve a sample based on destination health.
- Graceful Drop: Discard data when no safe delivery path exists.
These mechanisms ensure delivery attempts do not overwhelm unhealthy gateways, while preserving observability where possible. When deploying at scale or in dynamic environments, enable circuit breakers and configure health checks to support both routing logic and fault resilience.
See Gateway Output Node and Circuit Breaker for configuration details.
Routing Third-Party Agents to Gateway Pipelines
When ingesting telemetry from OTLP collectors or other third-party agents, send data directly to a gateway pipeline rather than routing it through node pipelines first.
Why Use Gateway Pipelines for Agent Data
Node pipelines run as DaemonSets, deploying one agent per Kubernetes node. They excel at collecting node-local data such as container logs from /var/log and host-level metrics. However, third-party agents already collect and batch telemetry before sending it over the network. Routing this data through node pipelines adds an unnecessary hop and wastes resources on every node.
Gateway pipelines run as Deployments that scale horizontally based on load. They are designed for:
- Aggregation: Receiving data from multiple sources and performing cross-source operations
- Trace correlation: Assembling complete traces from spans that originate on different nodes
- Service-level metrics: Calculating metrics that require visibility across the entire cluster
- Deduplication: Removing duplicate data from overlapping collection sources
Trace Context Preservation
Distributed traces span multiple nodes. A node pipeline only sees the spans that happen to land on its node, making trace-level operations like tail sampling impossible. A gateway pipeline receives all spans from the cluster, enabling:
- Complete trace assembly and correlation
- Accurate service map generation
- End-to-end latency calculations
- Tail sampling decisions based on full trace context
Resource Efficiency
Sending agent data to node pipelines means every node runs processing logic for data that will immediately be forwarded elsewhere. This wastes CPU and memory on each node. By pointing agents directly at a gateway Service endpoint, you avoid this overhead and simplify your network architecture.
Typical Pattern
Use the following pattern for mixed deployments:
- Node pipelines: Collect node-local data (container logs, host metrics) via DaemonSet
- Gateway pipelines: Receive pushed telemetry from OTLP collectors and third-party agents via Deployment
Configure your OTLP exporter to send traces and metrics to the gateway pipeline’s ED Pipeline Source endpoint. For OTLP configuration details, see Ingest from an OTLP Source.
For agentless scenarios where you cannot deploy Edge Delta agents, consider Cloud Pipelines as an alternative. To optimize agent resource consumption in your deployments, see Reducing Agent Resource Consumption.