Configuring the Edge Delta Agent
Use Visual Pipelines or a text editor to configure the agent.
less than a minute
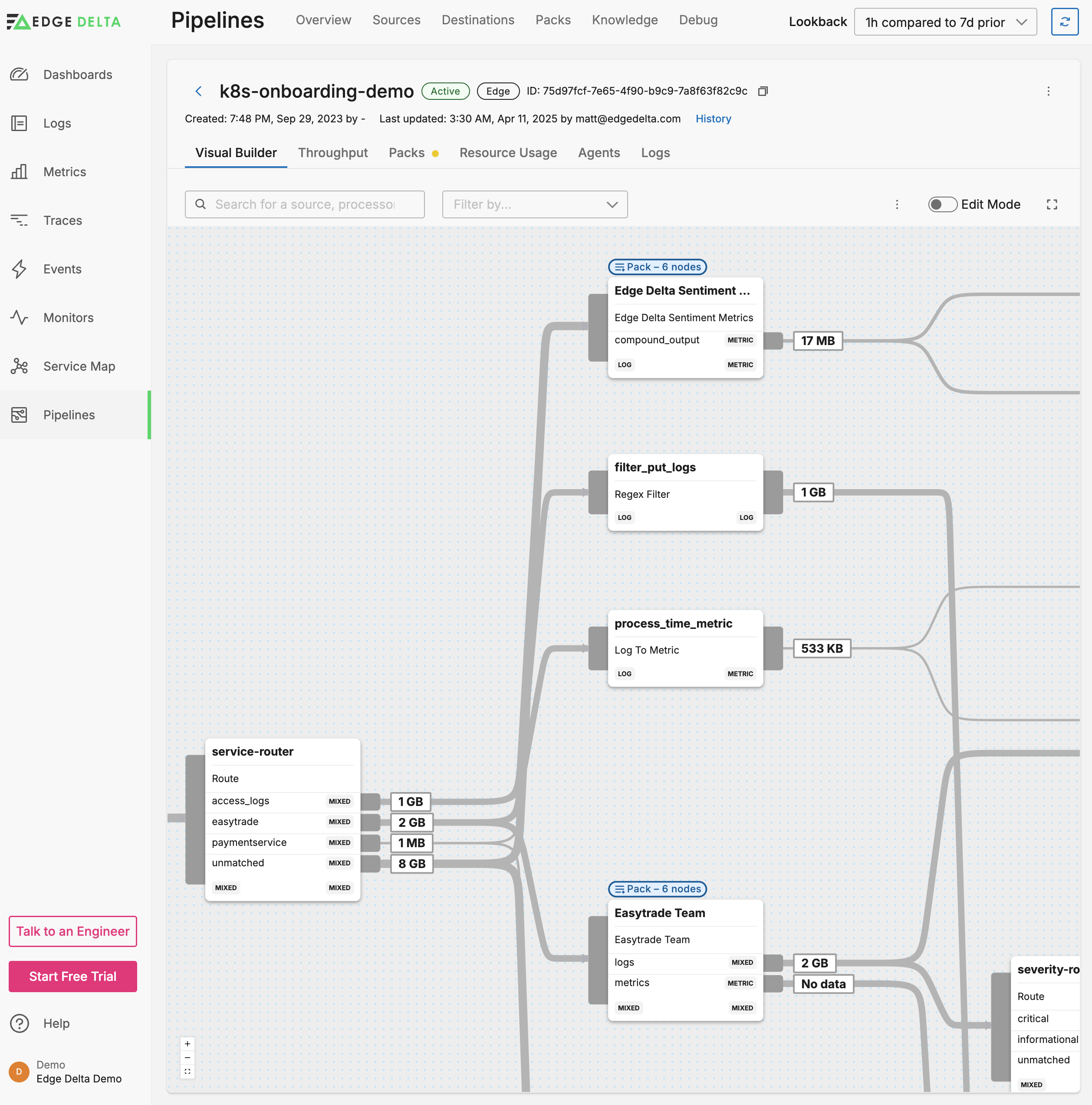
Visual Pipelines is a tool you can use to view and modify your data pipeline configuration.
The Visual Pipelines tool requires agents with a version 0.1.71 or higher. See here for more information.
The v3 configuration structure is a graph consisting of three types of nodes, the links between them, and the data handled by the pipeline:
The pipeline lists the outgoing data rate for each node. Using this view you can quickly see how the configuration contributes to the overall pipeline efficiency.
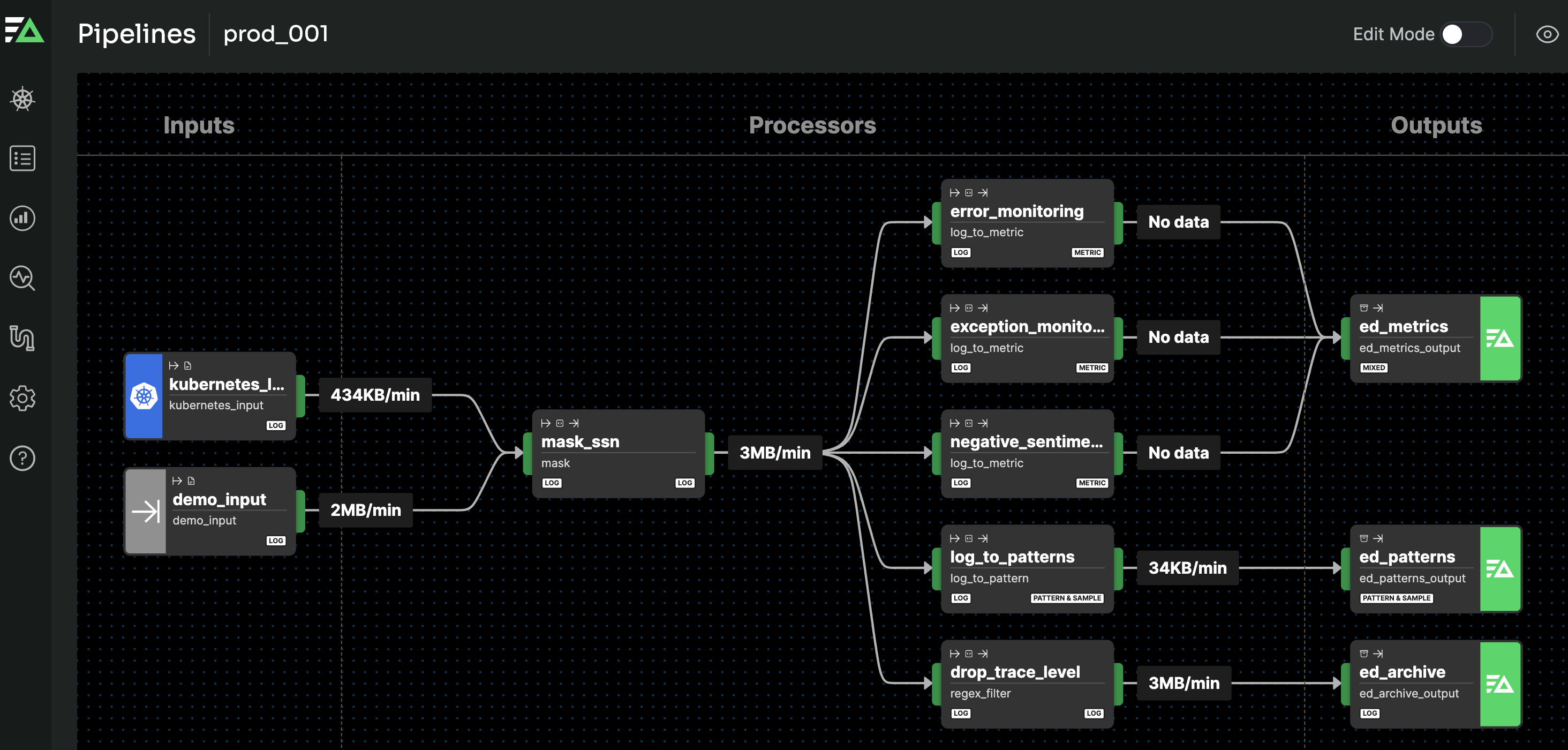
See Configuring the Agent to build your data pipeline.
Some configuration v3 parameters are advanced or in beta, requiring them to be configured in YAML using a text editor rather than Visual Pipelines.
After making changes to an agent configuration using the Edge Delta Web UI, there is no need to restart or reinstall the Edge Delta agent. The configuration settings will be automatically applied after a few minutes.
Use Visual Pipelines or a text editor to configure the agent.
Connect nodes to build your pipeline.
Data items are handled by nodes and transported by links.
Use CEL Custom Macros to reference log fields.
Test node functions to design and build effective pipelines.
Input Nodes in v3 configurations.
Processor nodes in v3 configurations.
Output nodes in Visual Pipelines.
Methods for fine-tuning your configuration.
Compound Nodes in the Edge Delta Visual Pipeline.
Diagnostics Nodes in the Edge Delta Visual Pipeline.
Global agent configuration options.