Edge Delta Log Patterns
2 minute read
Pattern Detection
The Edge Delta agent uses a proprietary algorithm to automatically detect repeated patterns in log data on the edge. This allows it to optimize data by reporting patterns and their frequency rather than streaming the full log data. Variant values within a pattern are expressed as a wildcard (*).
Log to Pattern
Log patterns are detected by pipeline nodes that are configured on an Edge Delta agent. The log to pattern node will track and report the most frequently occurring patterns for the default or specified interval, and it will send a specified number of full log samples for each pattern.
Sentiment Analysis
Every pattern detected by the Edge Delta agent is analyzed to check for negative sentiment. Negative sentiment is determined by checking for the presence of specific keywords or Golang Regex patterns. Some keywords such as debug are considered neutralizing because they automatically offset negative keyword matches in the pattern. Sentiment keywords are applied to all Fleets within an account.
You can specify Golang Regex such as alert([=\s\*]+|$) or string literals such as broken. Literals are not case sensitive.

Note: You must reload the fleet after changing sentiment keywords.
Pattern Visualization
Log patterns detected by the Edge Delta agent can be viewed in the Edge Delta web app.
Edge Delta Web App
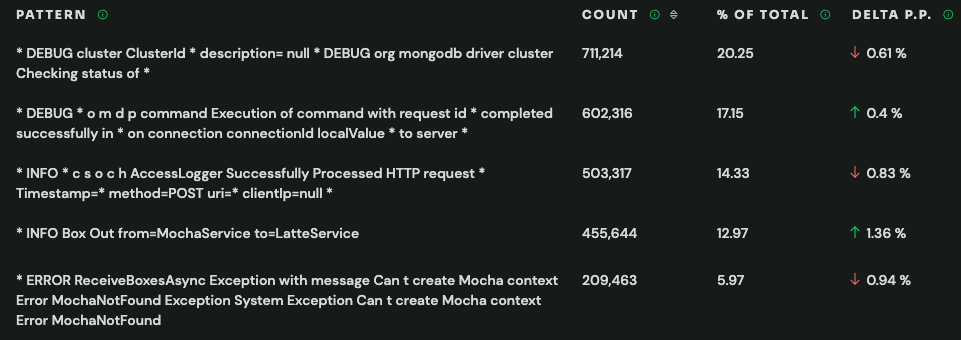
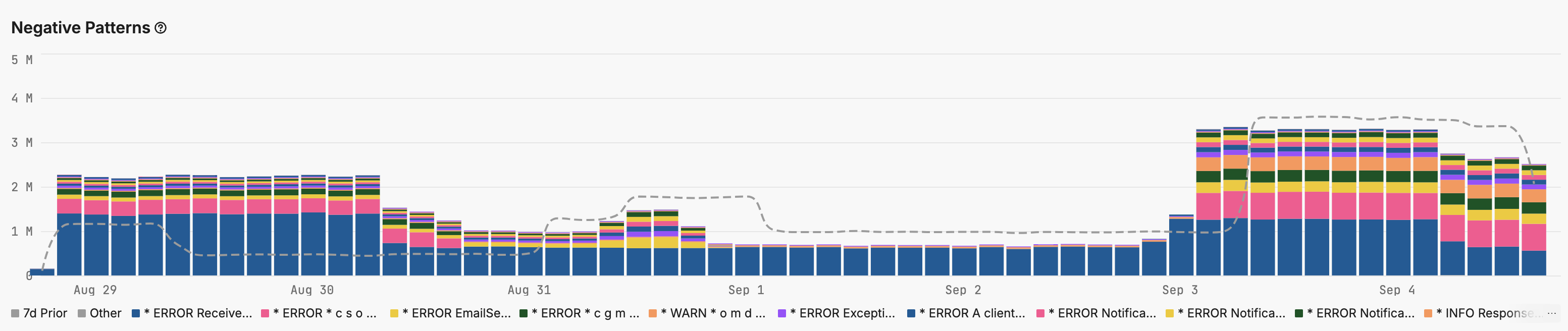
The Patterns tab of the Logs page shows a Negative Patterns pane listing all patterns with negative sentiment.
3rd Party Tools
Patterns can also be viewed in any streaming destination that accepts log data.
Anomaly Detection in Log Patterns
Once pattern data is sent to the Edge Delta backend, it can be further analyzed for anomalies. See anomaly detection for more details.